 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Volume Preserving-based Feature Fusion Approach to Group-Level Expression Recognition on Crowd Videos
Paper and Code
Nov 28, 2018
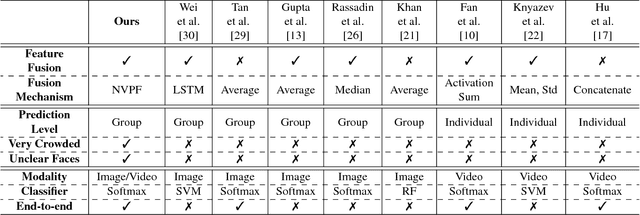

Group-level emotion recognition (ER) is a growing research area as the demands for assessing crowds of all sizes is becoming an interest in both the security arena and social media. This work investigates group-level expression recognition on crowd videos where information is not only aggregated across a variable length sequence of frames but also over the set of faces within each frame to produce aggregated recognition results. In this paper, we propose an effective deep feature level fusion mechanism to model the spatial-temporal information in the crowd videos. Furthermore, we extend our proposed NVP fusion mechanism to temporal NVP fussion appoarch to learn the temporal information between frames. In order to demonstrate the robustness and effectiveness of each component in the proposed approach, three experiments were conducted: (i) evaluation on the AffectNet database to benchmark the proposed emoNet for recognizing facial expression; (ii) evaluation on EmotiW2018 to benchmark the proposed deep feature level fusion mechanism NVPF; and, (iii) examine the proposed TNVPF on an innovative Group-level Emotion on Crowd Videos (GECV) dataset composed of 627 videos collected from social media. GECV dataset is a collection of videos ranging in duration from 10 to 20 seconds of crowds of twenty (20) or more subjects and each video is labeled as positive, negative, or neutral.