 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEIGAN: Towards Compositional Image Generation by Simultaneously Learning to Segment, Enhance, and Inpaint
Paper and Code
Nov 19, 2018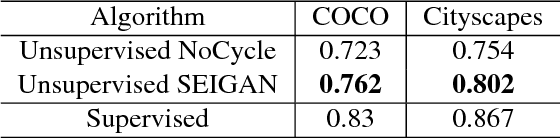
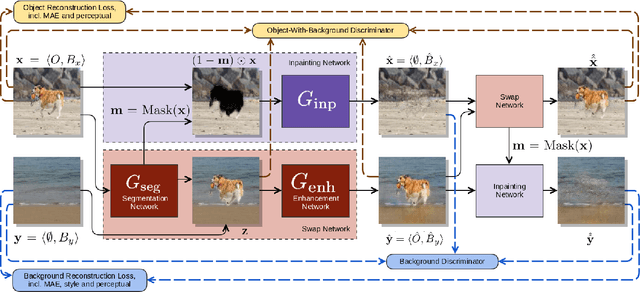
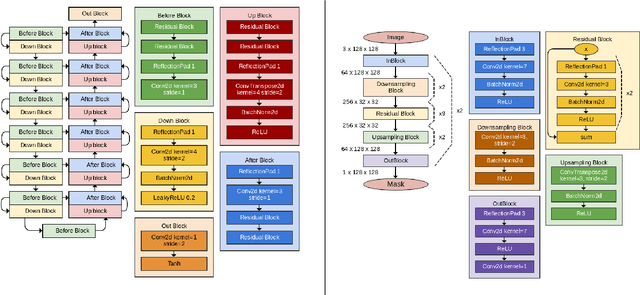
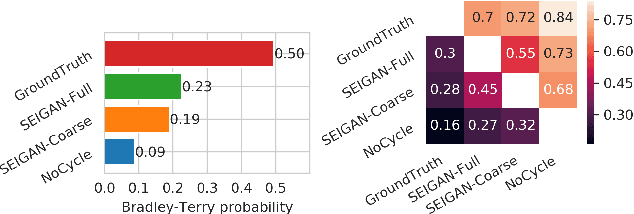
We present a novel approach to image manipulation and understanding by simultaneously learning to segment object masks, paste objects to another background image, and remove them from original images. For this purpose, we develop a novel generative model for compositional image generation, SEIGAN (Segment-Enhance-Inpaint Generative Adversarial Network), which learns these three operations together in an adversarial architecture with additional cycle consistency losses. To train, SEIGAN needs only bounding box supervision and does not require pairing or ground truth masks. SEIGAN produces better generated images (evaluated by human assessors) than other approaches and produces high-quality segmentation masks, improving over other adversarially trained approaches and getting closer to the results of fully supervised training.