 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward learning from human preferences and demonstrations in Atari
Paper and Code
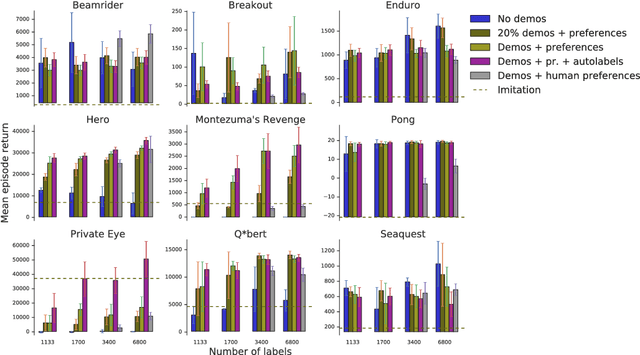
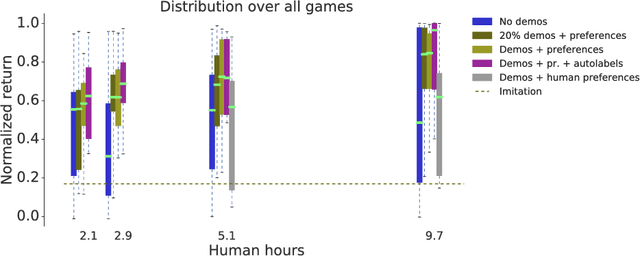
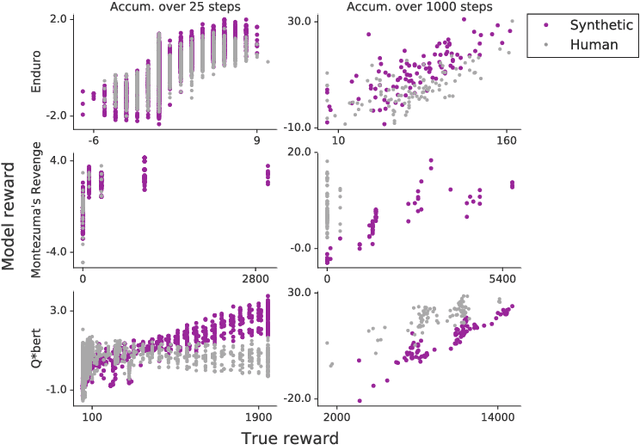
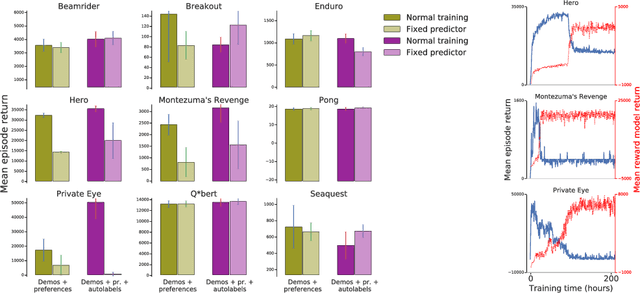
To solve complex real-world problems with reinforcement learning, we cannot rely on manually specified reward functions. Instead, we can have humans communicate an objective to the agent directly. In this work, we combine two approaches to learning from human feedback: expert demonstrations and trajectory preferences. We train a deep neural network to model the reward function and use its predicted reward to train an DQN-based deep reinforcement learning agent on 9 Atari games. Our approach beats the imitation learning baseline in 7 games and achieves strictly superhuman performance on 2 games without using game rewards. Additionally, we investigate the goodness of fit of the reward model, present some reward hacking problems, and study the effects of noise in the human labels.