 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing deep CNN-based utterance embeddings for acoustic model adaptation
Paper and Code
Nov 12, 2018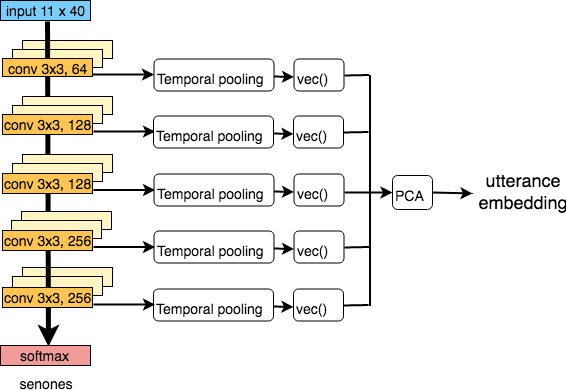
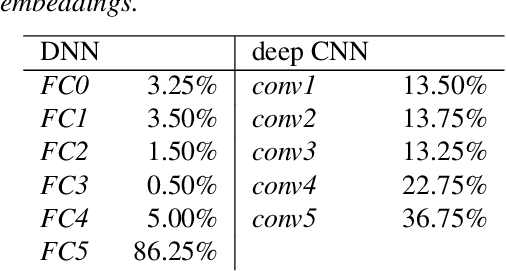
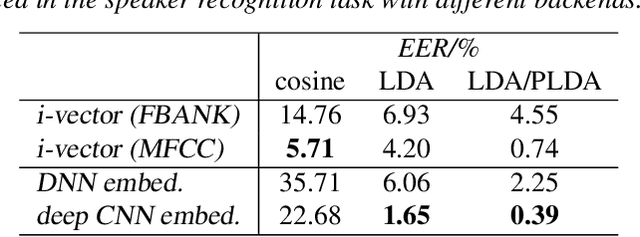
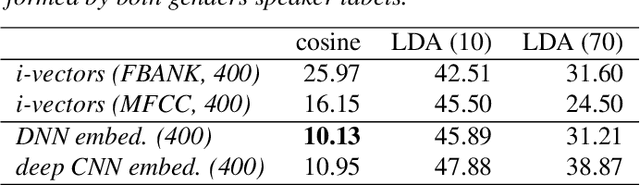
We explore why deep convolutional neural networks (CNNs) with small two-dimensional kernels, primarily used for modeling spatial relations in images, are also effective in speech recognition. We analyze the representations learned by deep CNNs and compare them with deep neural network (DNN) representations and i-vectors, in the context of acoustic model adaptation. To explore whether interpretable information can be decoded from the learned representations we evaluate their ability to discriminate between speakers, acoustic conditions, noise type, and gender using the Aurora-4 dataset. We extract both whole model embeddings (to capture the information learned across the whole network) and layer-specific embeddings which enable understanding of the flow of information across the network. We also use learned representations as the additional input for a time-delay neural network (TDNN) for the Aurora-4 and MGB-3 English datasets. We find that deep CNN embeddings outperform DNN embeddings for acoustic model adaptation and auxiliary features based on deep CNN embeddings result in similar word error rates to i-vectors.