 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen CTC Training Meets Acoustic Landmarks
Paper and Code
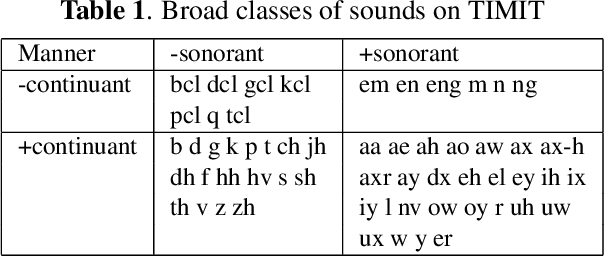
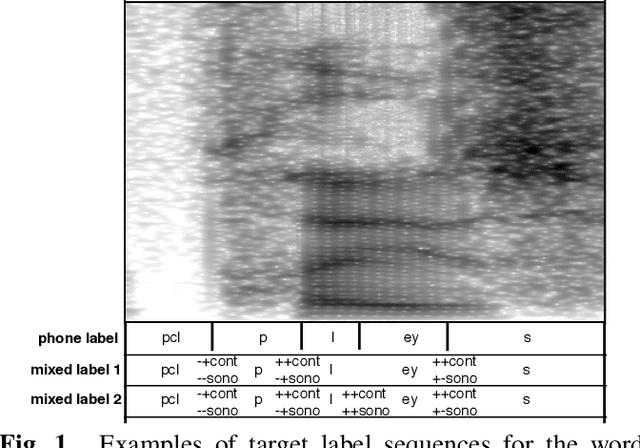
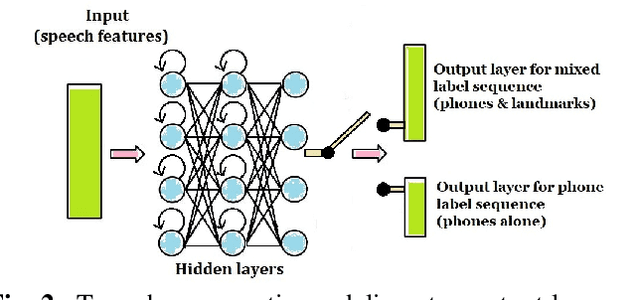
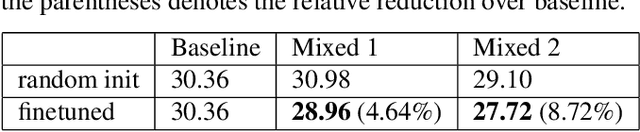
Connectionist temporal classification (CTC) training criterion provides an alternative acoustic model (AM) training strategy for automatic speech recognition in an end-to-end fashion. Although CTC criterion benefits acoustic modeling without needs of time-aligned phonetics transcription, it remains in need of efforts of tweaking to convergence, especially in the resource-constrained scenario. In this paper, we proposed to improve CTC training by incorporating acoustic landmarks. We tailored a new set of acoustic landmarks to help CTC training converge more quickly while also reducing recognition error rates. We leveraged new target label sequences mixed with both phone and manner changes to guide CTC training. Experiments on TIMIT demonstrated that CTC based acoustic models converge faster and smoother significantly when they are augmented by acoustic landmarks. The models pretrained with mixed target labels can be finetuned furthermore, which reduced phone error rate by 8.72% on TIMIT. The consistent performance gain is also observed on reduced TIMIT and WSJ as well, in which case, we are the first to succeed in testing the effectiveness of acoustic landmark theory on mid-sized ASR tasks.