 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sparse Hierarchical Graph Classifiers
Paper and Code
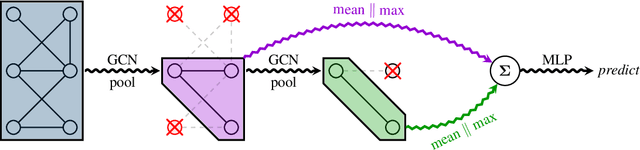
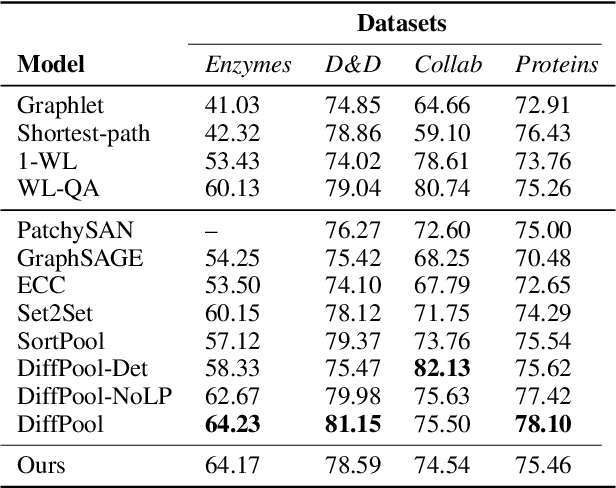
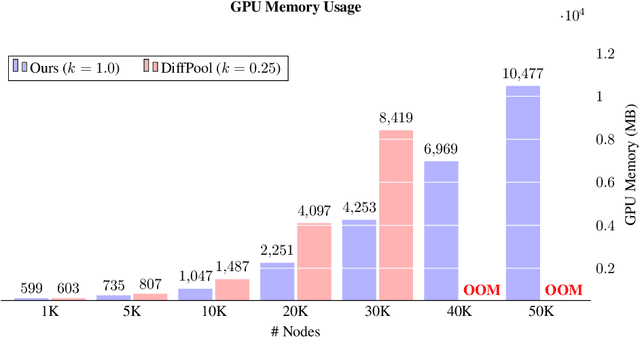
Recent advances in representation learning on graphs, mainly leveraging graph convolutional networks, have brought a substantial improvement on many graph-based benchmark tasks. While novel approaches to learning node embeddings are highly suitable for node classification and link prediction, their application to graph classification (predicting a single label for the entire graph) remains mostly rudimentary, typically using a single global pooling step to aggregate node features or a hand-designed, fixed heuristic for hierarchical coarsening of the graph structure. An important step towards ameliorating this is differentiable graph coarsening---the ability to reduce the size of the graph in an adaptive, data-dependent manner within a graph neural network pipeline, analogous to image downsampling within CNNs. However, the previous prominent approach to pooling has quadratic memory requirements during training and is therefore not scalable to large graphs. Here we combine several recent advances in graph neural network design to demonstrate that competitive hierarchical graph classification results are possible without sacrificing sparsity. Our results are verified on several established graph classification benchmarks, and highlight an important direction for future research in graph-based neural networks.