 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Coverage and the Generalization Ability of Neural Word Sense Disambiguation through Hypernymy and Hyponymy Relationships
Paper and Code
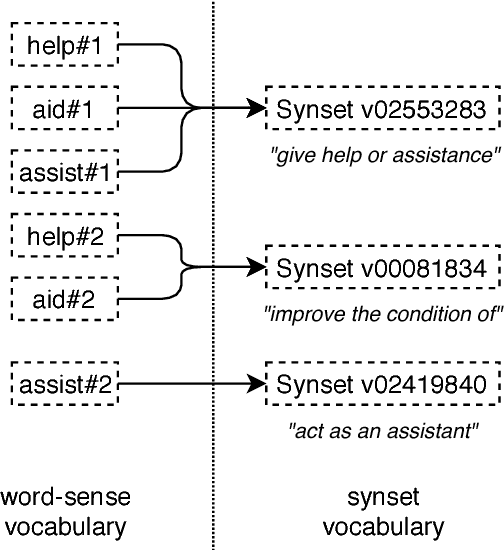

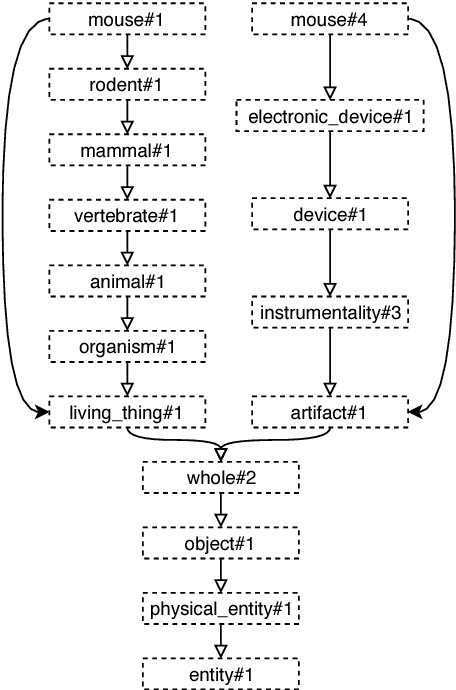
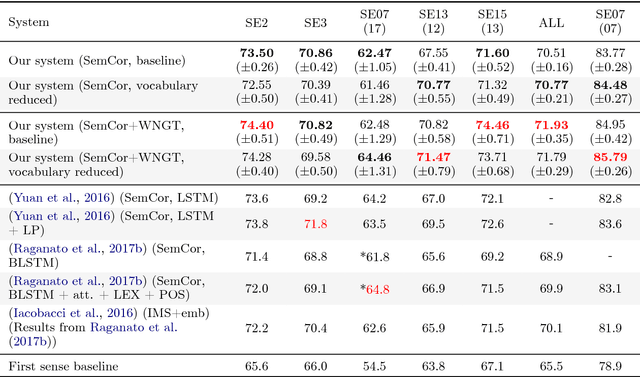
In Word Sense Disambiguation (WSD), the predominant approach generally involves a supervised system trained on sense annotated corpora. The limited quantity of such corpora however restricts the coverage and the performance of these systems. In this article, we propose a new method that solves these issues by taking advantage of the knowledge present in WordNet, and especially the hypernymy and hyponymy relationships between synsets, in order to reduce the number of different sense tags that are necessary to disambiguate all words of the lexical database. Our method leads to state of the art results on most WSD evaluation tasks, while improving the coverage of supervised systems, reducing the training time and the size of the models, without additional training data. In addition, we exhibit results that significantly outperform the state of the art when our method is combined with an ensembling technique and the addition of the WordNet Gloss Tagged as training corpus.