 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Regularization of Stochastic Gradient Descent in Natural Language Processing: Observations and Implications
Paper and Code
Nov 01, 2018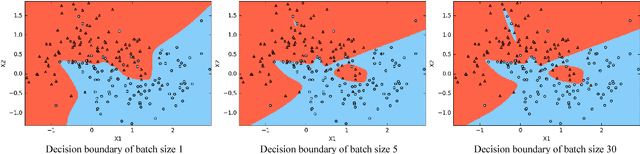
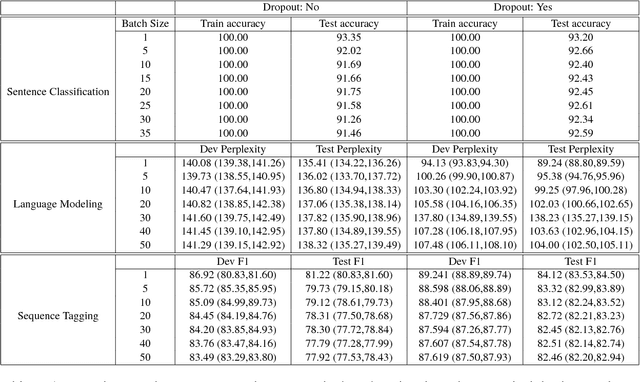
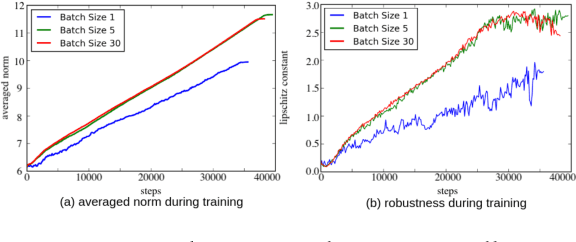

Deep neural networks with remarkably strong generalization performances are usually over-parameterized. Despite explicit regularization strategies are used for practitioners to avoid over-fitting, the impacts are often small. Some theoretical studies have analyzed the implicit regularization effect of stochastic gradient descent (SGD) on simple machine learning models with certain assumptions. However, how it behaves practically in state-of-the-art models and real-world datasets is still unknown. To bridge this gap, we study the role of SGD implicit regularization in deep learning systems. We show pure SGD tends to converge to minimas that have better generalization performances in multiple natural language processing (NLP) tasks. This phenomenon coexists with dropout, an explicit regularizer. In addition, neural network's finite learning capability does not impact the intrinsic nature of SGD's implicit regularization effect. Specifically, under limited training samples or with certain corrupted labels, the implicit regularization effect remains strong. We further analyze the stability by varying the weight initialization range. We corroborate these experimental findings with a decision boundary visualization using a 3-layer neural network for interpretation. Altogether, our work enables a deepened understanding on how implicit regularization affects the deep learning model and sheds light on the future study of the over-parameterized model's generalization ability.