 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning First-to-Spike Policies for Neuromorphic Control Using Policy Gradients
Paper and Code
Oct 25, 2018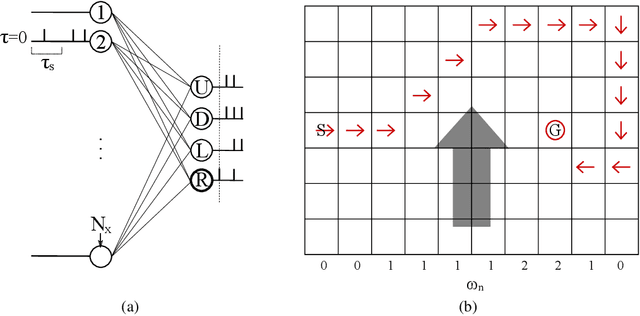
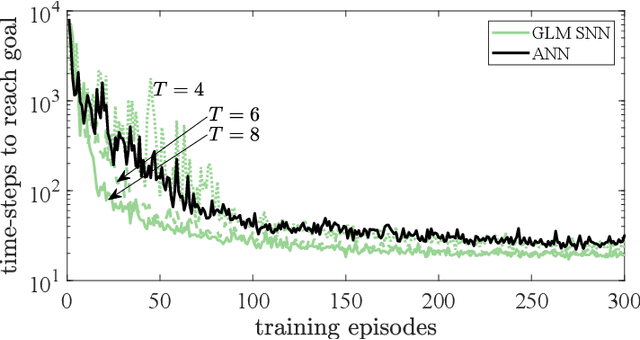
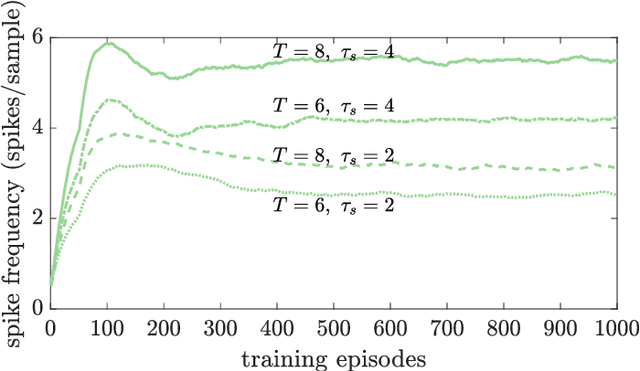
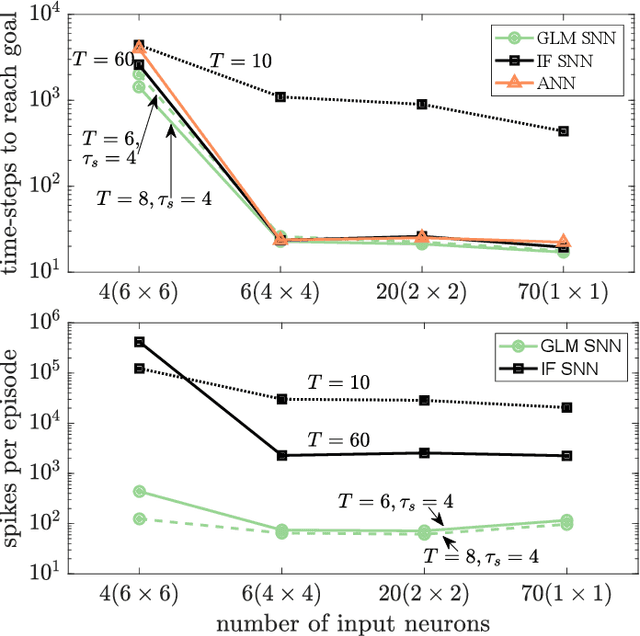
Artificial Neural Networks (ANNs) are currently being used as function approximators in many state-of-the-art Reinforcement Learning (RL) algorithms. Spiking Neural Networks (SNNs) have been shown to drastically reduce the energy consumption of ANNs by encoding information in sparse temporal binary spike streams, hence emulating the communication mechanism of biological neurons. In this work, the use of SNNs as stochastic policies is explored under an energy-efficient first-to-spike action rule, whereby the action taken by the RL agent is determined by the occurrence of the first spike among the output neurons. A policy gradient-based algorithm is derived and implemented on a windy grid-world problem. Experimental results demonstrate the capability of SNNs as stochastic policies to gracefully trade energy consumption, as measured by the number of spikes, and control performance.