 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Generative Adversarial Networks With a Neural Network Discriminator: Local Training, Bayesian Models, and Continual Meta-Learning
Nov 02, 2021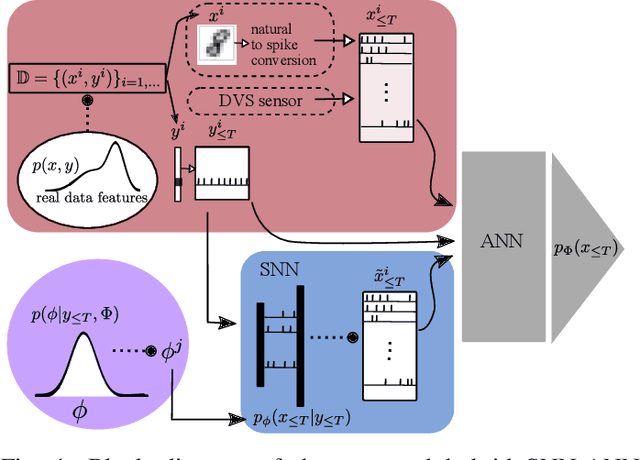
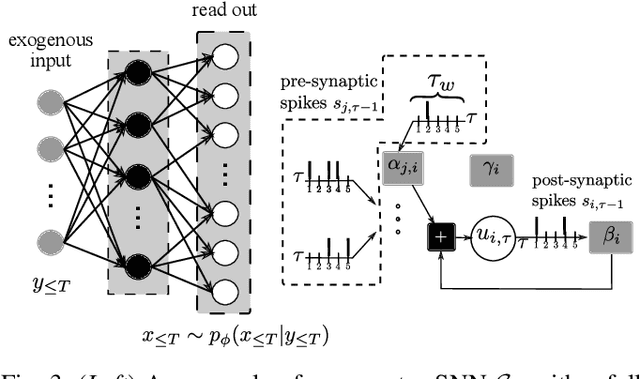
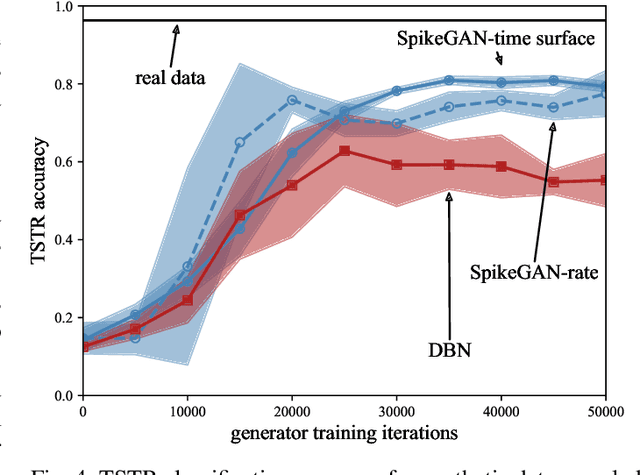
Neuromorphic data carries information in spatio-temporal patterns encoded by spikes. Accordingly, a central problem in neuromorphic computing is training spiking neural networks (SNNs) to reproduce spatio-temporal spiking patterns in response to given spiking stimuli. Most existing approaches model the input-output behavior of an SNN in a deterministic fashion by assigning each input to a specific desired output spiking sequence. In contrast, in order to fully leverage the time-encoding capacity of spikes, this work proposes to train SNNs so as to match distributions of spiking signals rather than individual spiking signals. To this end, the paper introduces a novel hybrid architecture comprising a conditional generator, implemented via an SNN, and a discriminator, implemented by a conventional artificial neural network (ANN). The role of the ANN is to provide feedback during training to the SNN within an adversarial iterative learning strategy that follows the principle of generative adversarial network (GANs). In order to better capture multi-modal spatio-temporal distribution, the proposed approach -- termed SpikeGAN -- is further extended to support Bayesian learning of the generator's weight. Finally, settings with time-varying statistics are addressed by proposing an online meta-learning variant of SpikeGAN. Experiments bring insights into the merits of the proposed approach as compared to existing solutions based on (static) belief networks and maximum likelihood (or empirical risk minimization).
Fast On-Device Adaptation for Spiking Neural Networks via Online-Within-Online Meta-Learning
Feb 21, 2021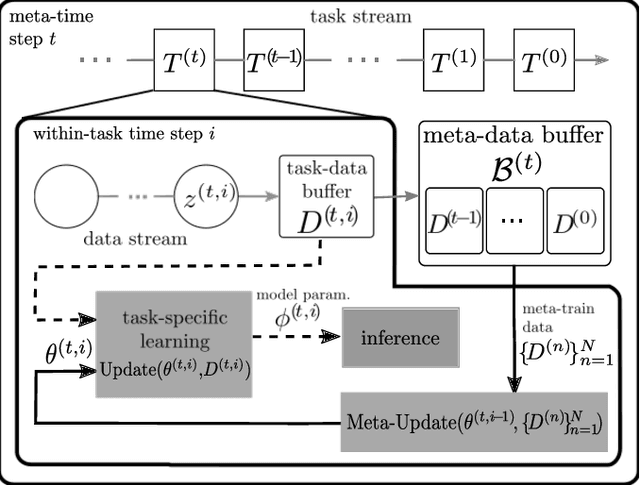
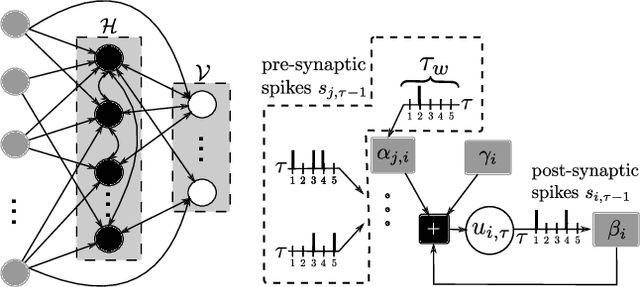
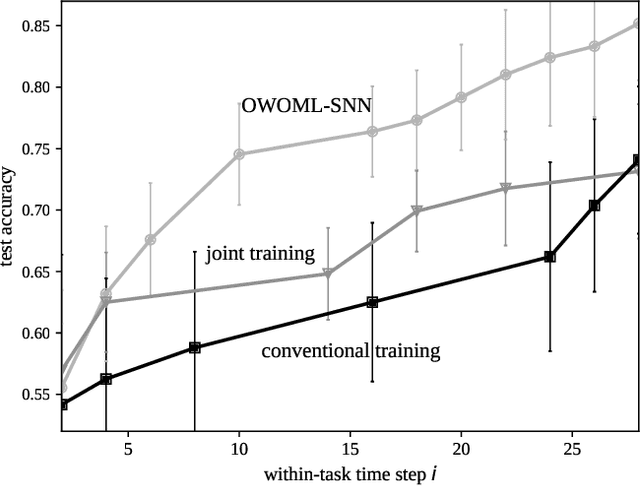
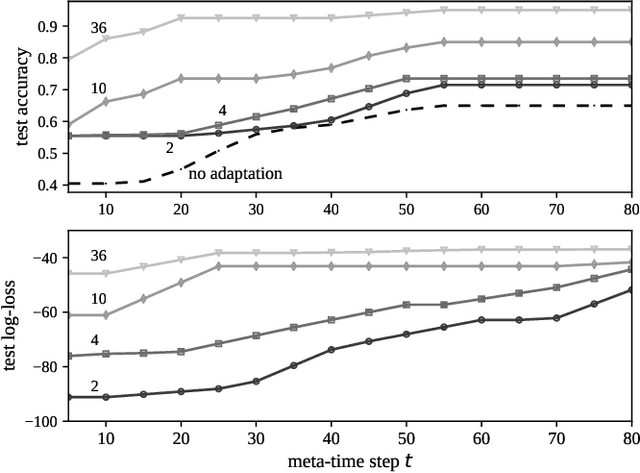
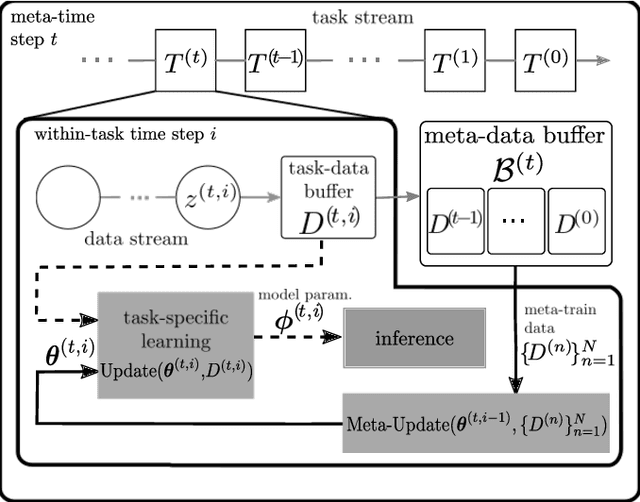
Spiking Neural Networks (SNNs) have recently gained popularity as machine learning models for on-device edge intelligence for applications such as mobile healthcare management and natural language processing due to their low power profile. In such highly personalized use cases, it is important for the model to be able to adapt to the unique features of an individual with only a minimal amount of training data. Meta-learning has been proposed as a way to train models that are geared towards quick adaptation to new tasks. The few existing meta-learning solutions for SNNs operate offline and require some form of backpropagation that is incompatible with the current neuromorphic edge-devices. In this paper, we propose an online-within-online meta-learning rule for SNNs termed OWOML-SNN, that enables lifelong learning on a stream of tasks, and relies on local, backprop-free, nested updates.
Learning First-to-Spike Policies for Neuromorphic Control Using Policy Gradients
Oct 25, 2018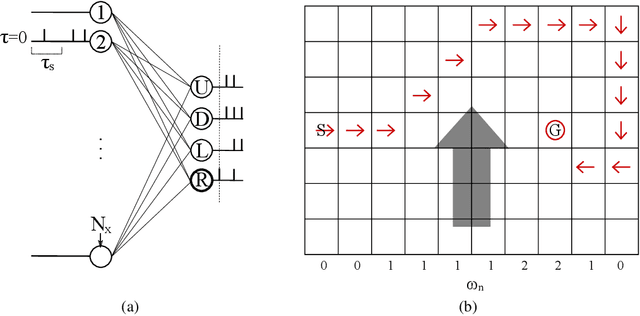
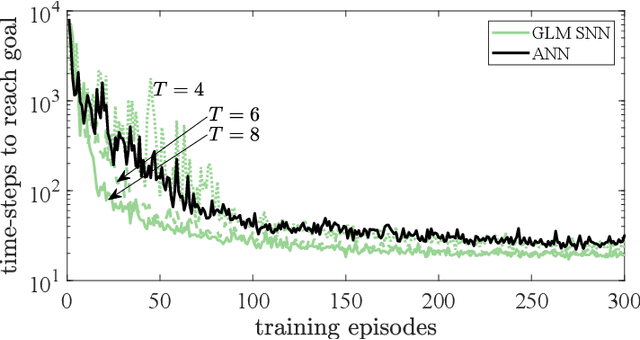
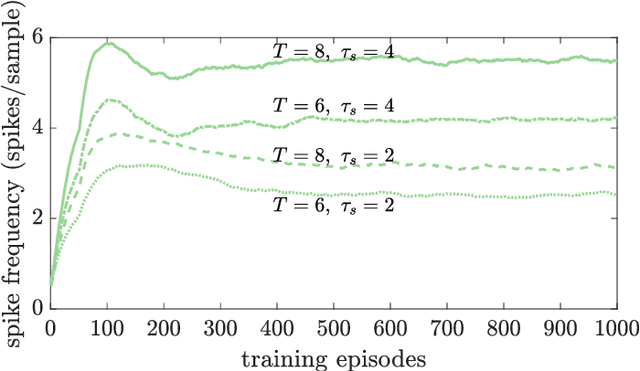
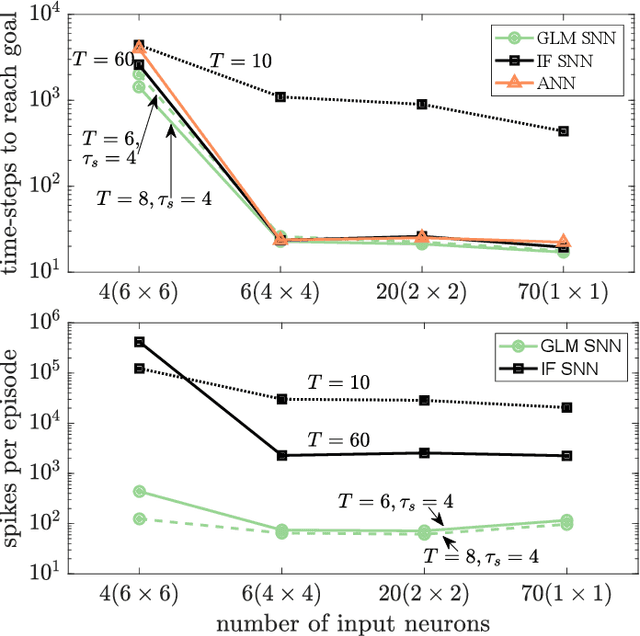
Artificial Neural Networks (ANNs) are currently being used as function approximators in many state-of-the-art Reinforcement Learning (RL) algorithms. Spiking Neural Networks (SNNs) have been shown to drastically reduce the energy consumption of ANNs by encoding information in sparse temporal binary spike streams, hence emulating the communication mechanism of biological neurons. In this work, the use of SNNs as stochastic policies is explored under an energy-efficient first-to-spike action rule, whereby the action taken by the RL agent is determined by the occurrence of the first spike among the output neurons. A policy gradient-based algorithm is derived and implemented on a windy grid-world problem. Experimental results demonstrate the capability of SNNs as stochastic policies to gracefully trade energy consumption, as measured by the number of spikes, and control performance.