 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISA Mapper: A Compute and Hardware Agnostic Deep Learning Compiler
Paper and Code
Oct 12, 2018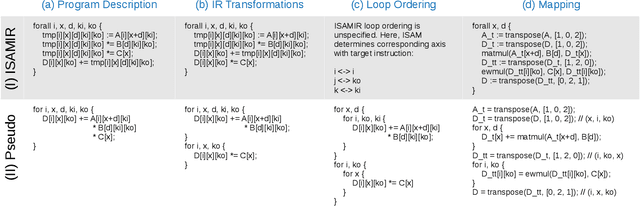
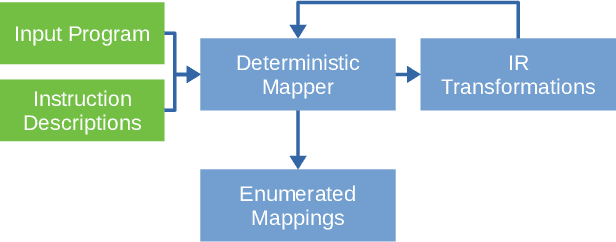
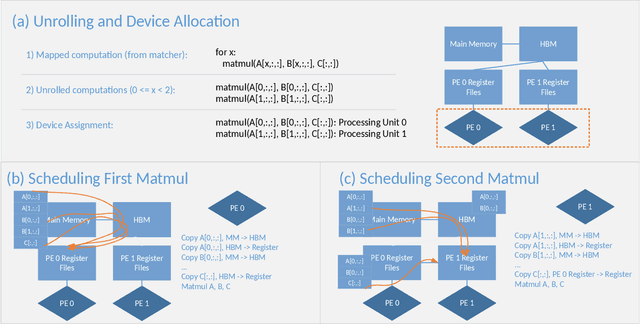
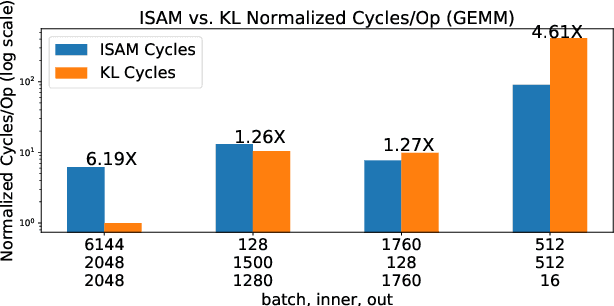
Domain specific accelerators present new challenges and opportunities for code generation onto novel instruction sets, communication fabrics, and memory architectures. In this paper we introduce an intermediate representation (IR) which enables both deep learning computational kernels and hardware capabilities to be described in the same IR. We then formulate and apply instruction mapping to determine the possible ways a computation can be performed on a hardware system. Next, our scheduler chooses a specific mapping and determines the data movement and computation order. In order to manage the large search space of mappings and schedules, we developed a flexible framework that allows heuristics, cost models, and potentially machine learning to facilitate this search problem. With this system, we demonstrate the automated extraction of matrix multiplication kernels out of recent deep learning kernels such as depthwise-separable convolution. In addition, we demonstrate two to five times better performance on DeepBench sized GEMMs and GRU RNN execution when compared to state-of-the-art (SOTA) implementations on new hardware and up to 85% of the performance for SOTA implementations on existing hardware.