Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast deep reinforcement learning using online adjustments from the past
Paper and Code
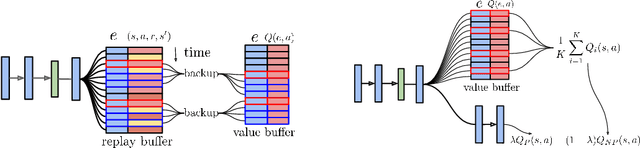
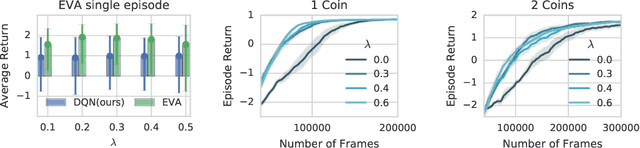
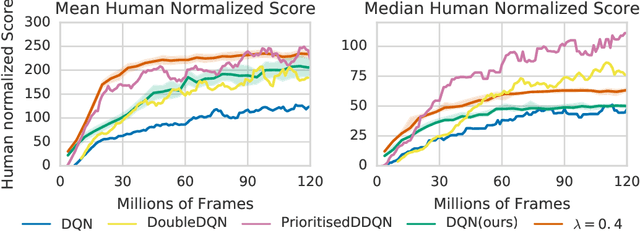
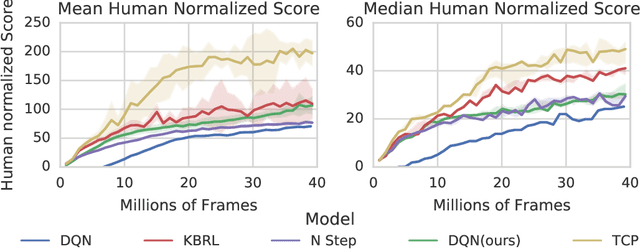
We propose Ephemeral Value Adjusments (EVA): a means of allowing deep reinforcement learning agents to rapidly adapt to experience in their replay buffer. EVA shifts the value predicted by a neural network with an estimate of the value function found by planning over experience tuples from the replay buffer near the current state. EVA combines a number of recent ideas around combining episodic memory-like structures into reinforcement learning agents: slot-based storage, content-based retrieval, and memory-based planning. We show that EVAis performant on a demonstration task and Atari games.
* Accepted at NIPS 2018
View paper on