Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast, Compact, Accurate Model for Language Identification of Codemixed Text
Paper and Code

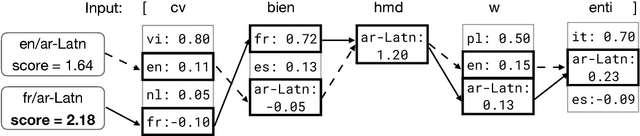
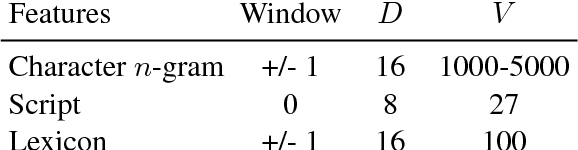
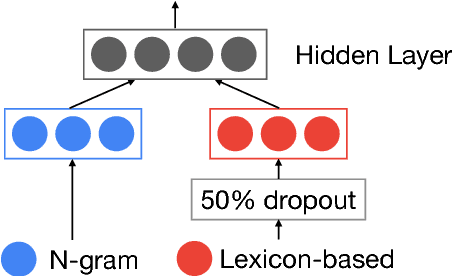
We address fine-grained multilingual language identification: providing a language code for every token in a sentence, including codemixed text containing multiple languages. Such text is prevalent online, in documents, social media, and message boards. We show that a feed-forward network with a simple globally constrained decoder can accurately and rapidly label both codemixed and monolingual text in 100 languages and 100 language pairs. This model outperforms previously published multilingual approaches in terms of both accuracy and speed, yielding an 800x speed-up and a 19.5% averaged absolute gain on three codemixed datasets. It furthermore outperforms several benchmark systems on monolingual language identification.
* EMNLP 2018
View paper on