 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-to-Video Person Re-Identification by Reusing Cross-modal Embeddings
Paper and Code

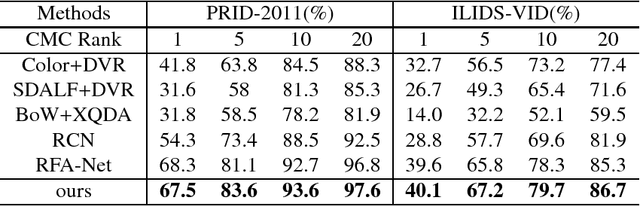
Image-to-video person re-identification identifies a target person by a probe image from quantities of pedestrian videos captured by non-overlapping cameras. Despite the great progress achieved,it's still challenging to match in the multimodal scenario,i.e. between image and video. Currently,state-of-the-art approaches mainly focus on the task-specific data,neglecting the extra information on the different but related tasks. In this paper,we propose an end-to-end neural network framework for image-to-video person reidentification by leveraging cross-modal embeddings learned from extra information.Concretely speaking,cross-modal embeddings from image captioning and video captioning models are reused to help learned features be projected into a coordinated space,where similarity can be directly computed. Besides,training steps from fixed model reuse approach are integrated into our framework,which can incorporate beneficial information and eventually make the target networks independent of existing models. Apart from that,our proposed framework resorts to CNNs and LSTMs for extracting visual and spatiotemporal features,and combines the strengths of identification and verification model to improve the discriminative ability of the learned feature. The experimental results demonstrate the effectiveness of our framework on narrowing down the gap between heterogeneous data and obtaining observable improvement in image-to-video person re-identification.