 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Ended Content-Style Recombination Via Leakage Filtering
Paper and Code
Sep 28, 2018
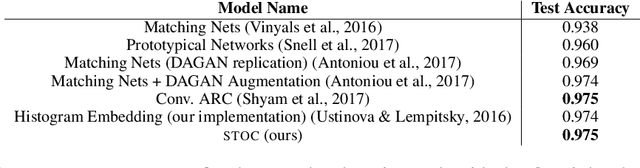

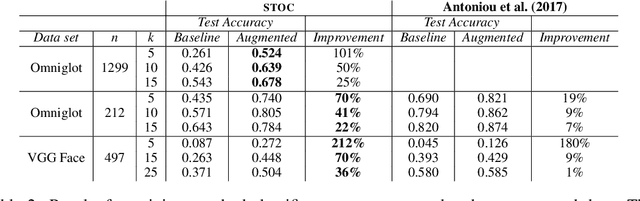
We consider visual domains in which a class label specifies the content of an image, and class-irrelevant properties that differentiate instances constitute the style. We present a domain-independent method that permits the open-ended recombination of style of one image with the content of another. Open ended simply means that the method generalizes to style and content not present in the training data. The method starts by constructing a content embedding using an existing deep metric-learning technique. This trained content encoder is incorporated into a variational autoencoder (VAE), paired with a to-be-trained style encoder. The VAE reconstruction loss alone is inadequate to ensure a decomposition of the latent representation into style and content. Our method thus includes an auxiliary loss, leakage filtering, which ensures that no style information remaining in the content representation is used for reconstruction and vice versa. We synthesize novel images by decoding the style representation obtained from one image with the content representation from another. Using this method for data-set augmentation, we obtain state-of-the-art performance on few-shot learning tasks.