 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Recommendation: Attack of the Learned Fake Users
Paper and Code
Sep 21, 2018

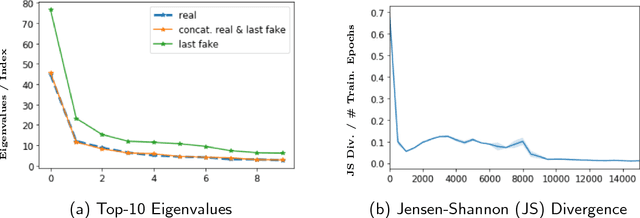
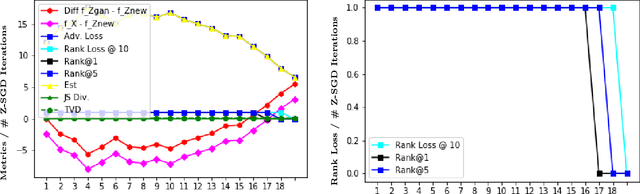
Can machine learning models for recommendation be easily fooled? While the question has been answered for hand-engineered fake user profiles, it has not been explored for machine learned adversarial attacks. This paper attempts to close this gap. We propose a framework for generating fake user profiles which, when incorporated in the training of a recommendation system, can achieve an adversarial intent, while remaining indistinguishable from real user profiles. We formulate this procedure as a repeated general-sum game between two players: an oblivious recommendation system $R$ and an adversarial fake user generator $A$ with two goals: (G1) the rating distribution of the fake users needs to be close to the real users, and (G2) some objective $f_A$ encoding the attack intent, such as targeting the top-K recommendation quality of $R$ for a subset of users, needs to be optimized. We propose a learning framework to achieve both goals, and offer extensive experiments considering multiple types of attacks highlighting the vulnerability of recommendation systems.