 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDéjà Vu: an empirical evaluation of the memorization properties of ConvNets
Paper and Code
Sep 17, 2018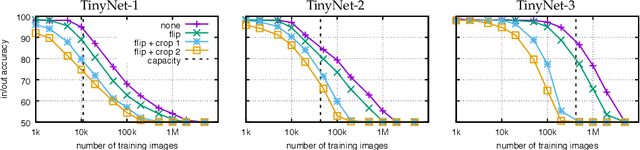
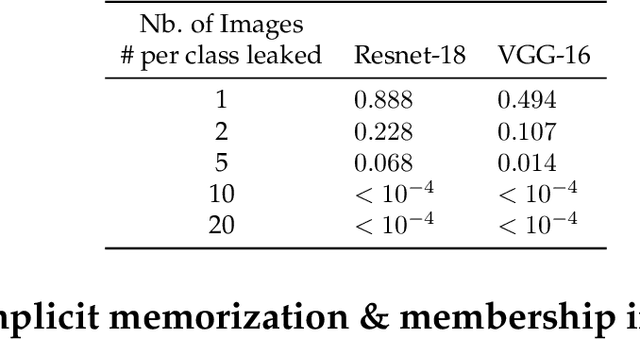
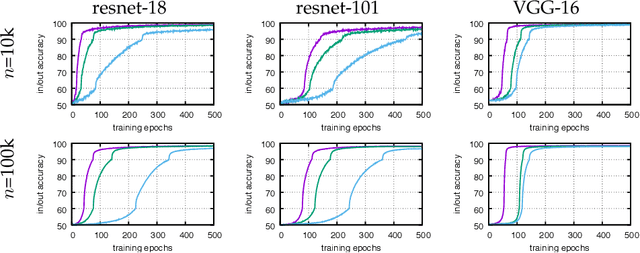
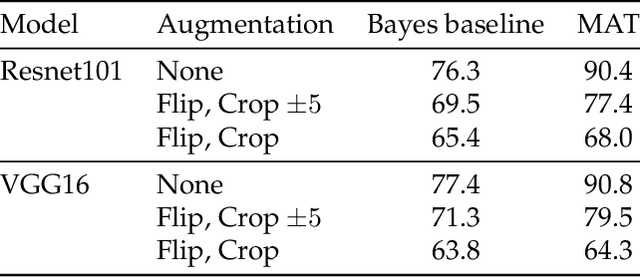
Convolutional neural networks memorize part of their training data, which is why strategies such as data augmentation and drop-out are employed to mitigate overfitting. This paper considers the related question of "membership inference", where the goal is to determine if an image was used during training. We consider it under three complementary angles. We show how to detect which dataset was used to train a model, and in particular whether some validation images were used at train time. We then analyze explicit memorization and extend classical random label experiments to the problem of learning a model that predicts if an image belongs to an arbitrary set. Finally, we propose a new approach to infer membership when a few of the top layers are not available or have been fine-tuned, and show that lower layers still carry information about the training samples. To support our findings, we conduct large-scale experiments on Imagenet and subsets of YFCC-100M with modern architectures such as VGG and Resnet.