 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Optimization of Gradient Boosting Decision Tree Algorithms
Paper and Code
Oct 25, 2018
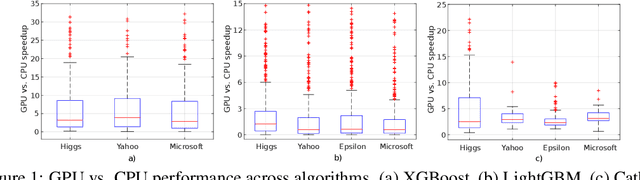
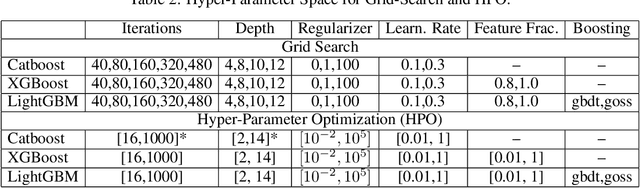
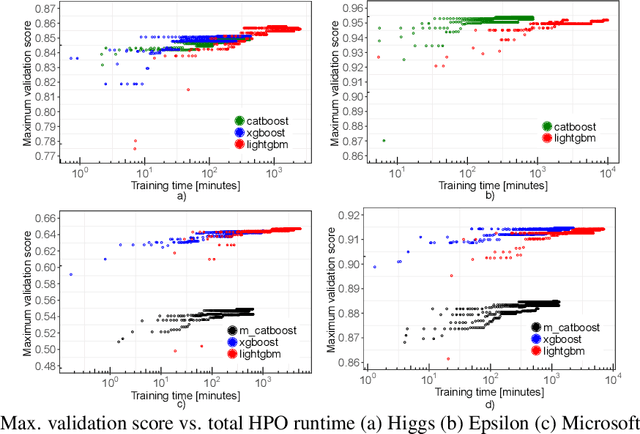
Gradient boosting decision trees (GBDTs) have seen widespread adoption in academia, industry and competitive data science due to their state-of-the-art performance in many machine learning tasks. One relative downside to these models is the large number of hyper-parameters that they expose to the end-user. To maximize the predictive power of GBDT models, one must either manually tune the hyper-parameters, or utilize automated techniques such as those based on Bayesian optimization. Both of these approaches are time-consuming since they involve repeatably training the model for different sets of hyper-parameters. A number of software GBDT packages have started to offer GPU acceleration which can help to alleviate this problem. In this paper, we consider three such packages: XGBoost, LightGBM and Catboost. Firstly, we evaluate the performance of the GPU acceleration provided by these packages using large-scale datasets with varying shapes, sparsities and learning tasks. Then, we compare the packages in the context of hyper-parameter optimization, both in terms of how quickly each package converges to a good validation score, and in terms of generalization performance.