 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Algorithms for Learning in Allocation Problems
Paper and Code
Aug 30, 2018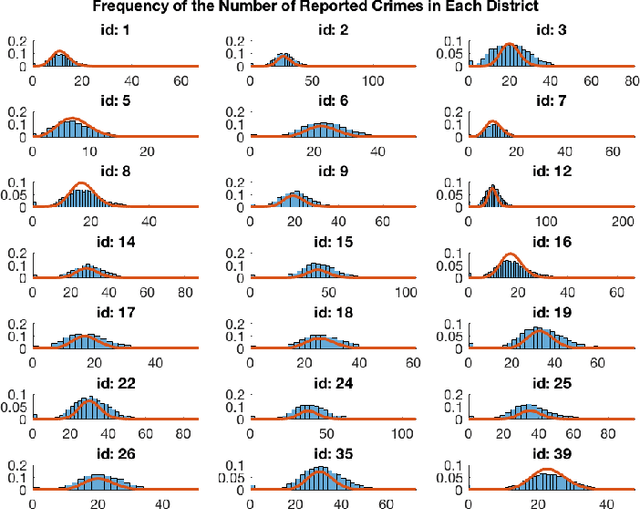
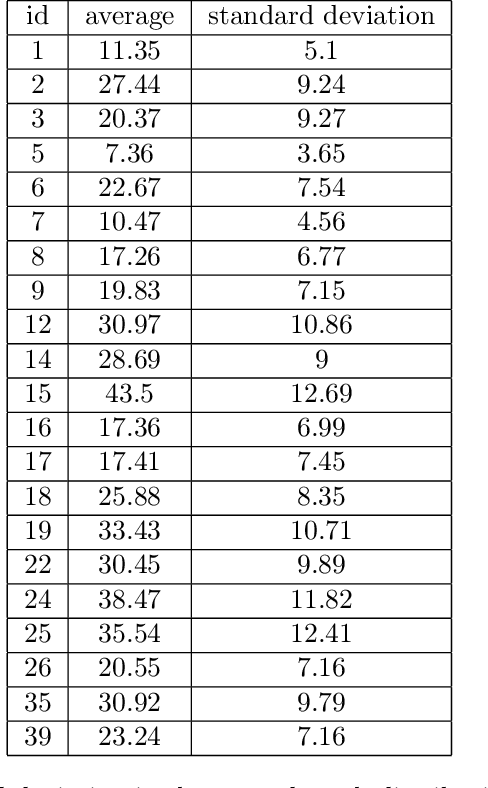
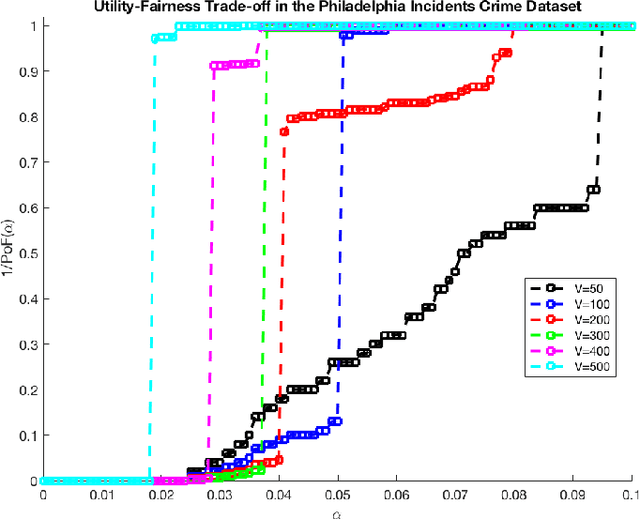
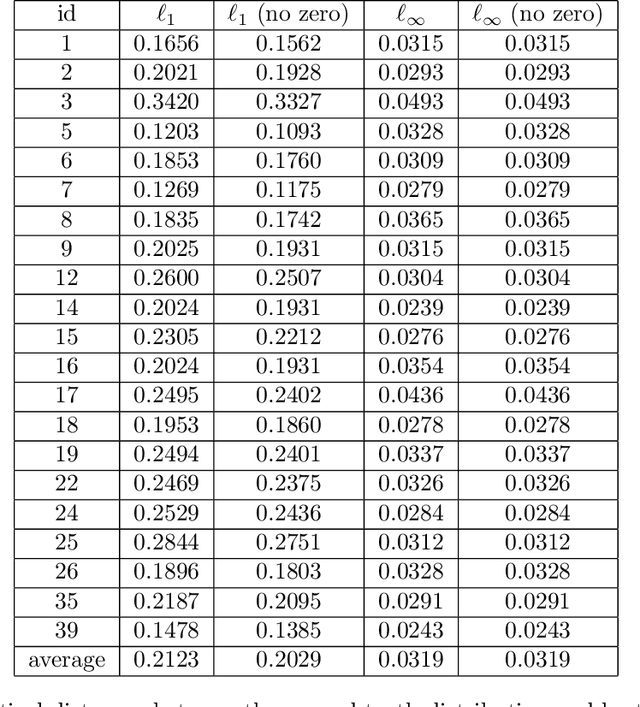
Settings such as lending and policing can be modeled by a centralized agent allocating a resource (loans or police officers) amongst several groups, in order to maximize some objective (loans given that are repaid or criminals that are apprehended). Often in such problems fairness is also a concern. A natural notion of fairness, based on general principles of equality of opportunity, asks that conditional on an individual being a candidate for the resource, the probability of actually receiving it is approximately independent of the individual's group. In lending this means that equally creditworthy individuals in different racial groups have roughly equal chances of receiving a loan. In policing it means that two individuals committing the same crime in different districts would have roughly equal chances of being arrested. We formalize this fairness notion for allocation problems and investigate its algorithmic consequences. Our main technical results include an efficient learning algorithm that converges to an optimal fair allocation even when the frequency of candidates (creditworthy individuals or criminals) in each group is unknown. The algorithm operates in a censored feedback model in which only the number of candidates who received the resource in a given allocation can be observed, rather than the true number of candidates. This models the fact that we do not learn the creditworthiness of individuals we do not give loans to nor learn about crimes committed if the police presence in a district is low. As an application of our framework, we consider the predictive policing problem. The learning algorithm is trained on arrest data gathered from its own deployments on previous days, resulting in a potential feedback loop that our algorithm provably overcomes. We empirically investigate the performance of our algorithm on the Philadelphia Crime Incidents dataset.