 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Statistical Machine Translation with Subword Translation of Out-of-Vocabulary Words
Paper and Code
Aug 16, 2018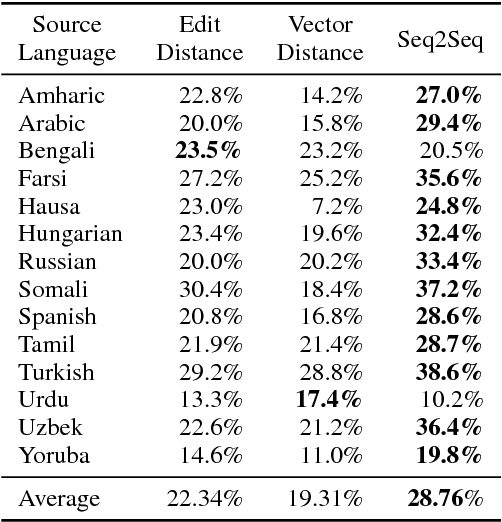

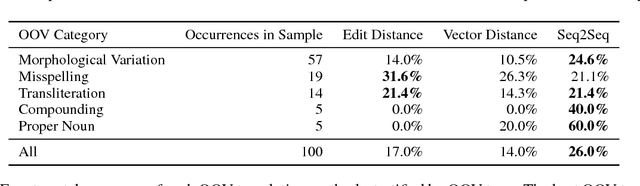
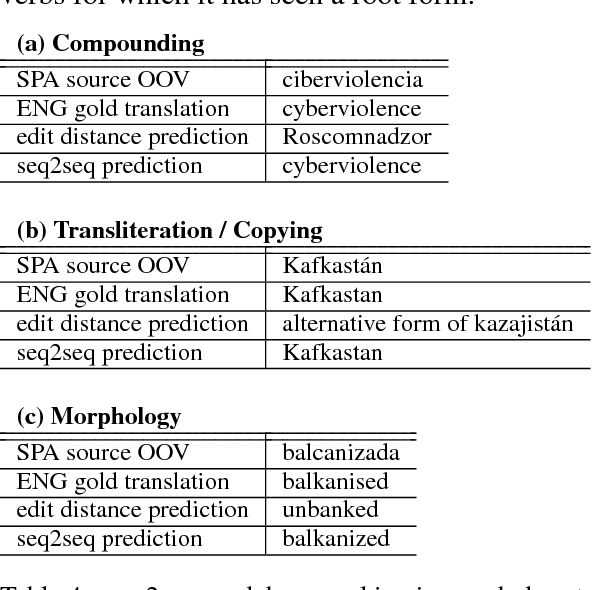
Most statistical machine translation systems cannot translate words that are unseen in the training data. However, humans can translate many classes of out-of-vocabulary (OOV) words (e.g., novel morphological variants, misspellings, and compounds) without context by using orthographic clues. Following this observation, we describe and evaluate several general methods for OOV translation that use only subword information. We pose the OOV translation problem as a standalone task and intrinsically evaluate our approaches on fourteen typologically diverse languages across varying resource levels. Adding OOV translators to a statistical machine translation system yields consistent BLEU gains (0.5 points on average, and up to 2.0) for all fourteen languages, especially in low-resource scenarios.