Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Dimensionality Reduction for Video Affect Classification: A Comparative Study
Paper and Code
Aug 08, 2018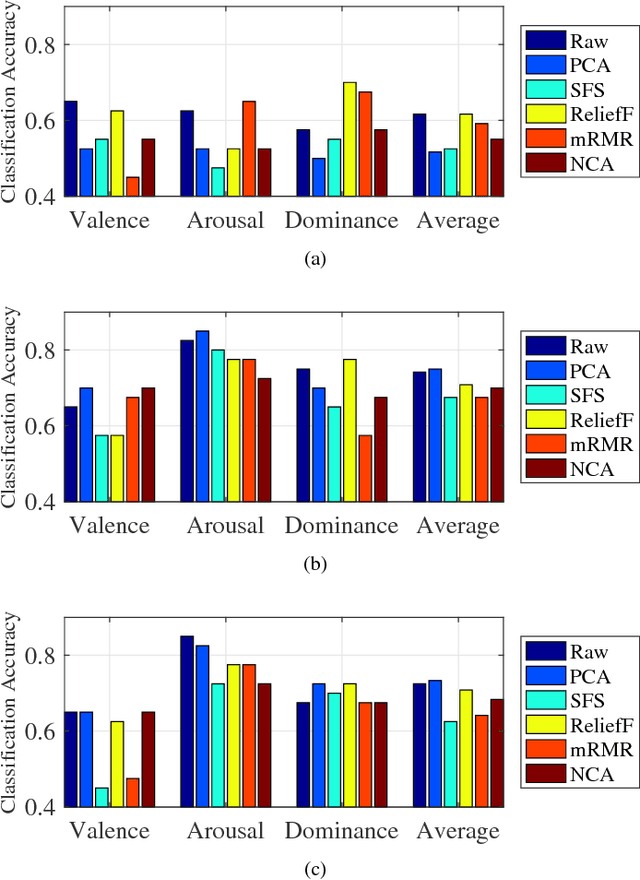

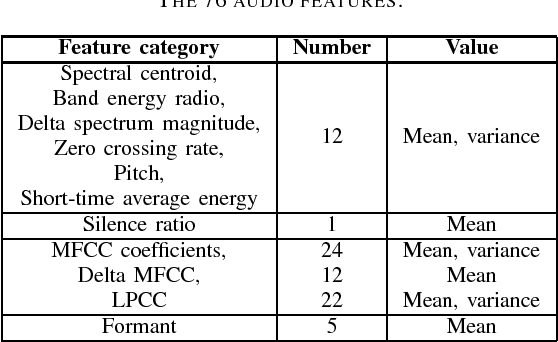
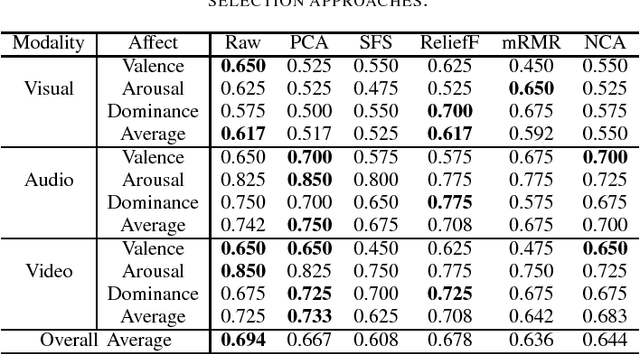
Affective computing has become a very important research area in human-machine interaction. However, affects are subjective, subtle, and uncertain. So, it is very difficult to obtain a large number of labeled training samples, compared with the number of possible features we could extract. Thus, dimensionality reduction is critical in affective computing. This paper presents our preliminary study on dimensionality reduction for affect classification. Five popular dimensionality reduction approaches are introduced and compared. Experiments on the DEAP dataset showed that no approach can universally outperform others, and performing classification using the raw features directly may not always be a bad choice.
View paper on