 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculumNet: Weakly Supervised Learning from Large-Scale Web Images
Paper and Code

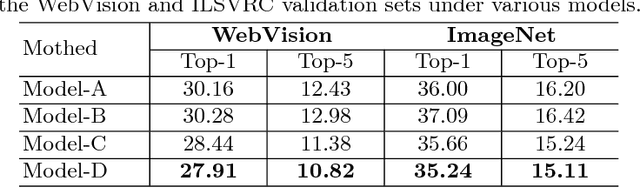
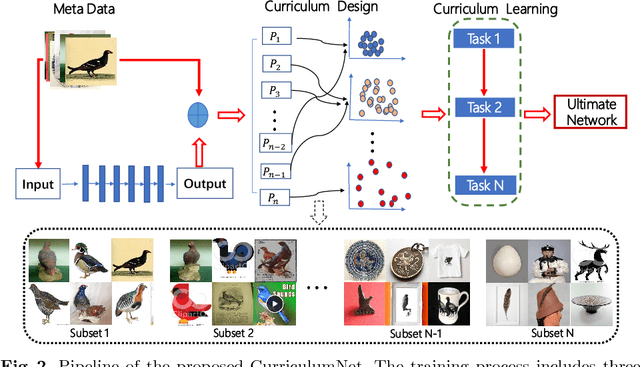

We present a simple yet efficient approach capable of training deep neural networks on large-scale weakly-supervised web images, which are crawled raw from the Internet by using text queries, without any human annotation. We develop a principled learning strategy by leveraging curriculum learning, with the goal of handling a massive amount of noisy labels and data imbalance effectively. We design a new learning curriculum by measuring the complexity of data using its distribution density in a feature space, and rank the complexity in an unsupervised manner. This allows for an efficient implementation of curriculum learning on large-scale web images, resulting in a high-performance CNN model, where the negative impact of noisy labels is reduced substantially. Importantly, we show by experiments that those images with highly noisy labels can surprisingly improve the generalization capability of the model, by serving as a manner of regularization. Our approaches obtain state-of-the-art performance on four benchmarks: WebVision, ImageNet, Clothing-1M and Food-101. With an ensemble of multiple models, we achieved a top-5 error rate of 5.2% on the WebVision challenge for 1000-category classification. This result was the top performance by a wide margin, outperforming second place by a nearly 50% relative error rate. Code and models are available at: https://github.com/MalongTech/CurriculumNet .