 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN driven Speaker Independent Audio-Visual Mask Estimation for Speech Separation
Paper and Code
Jul 31, 2018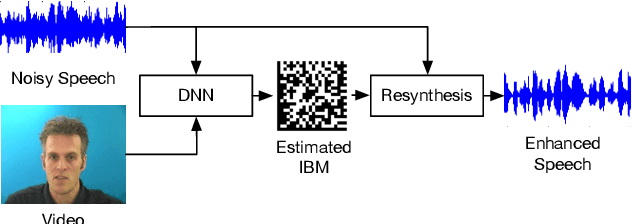

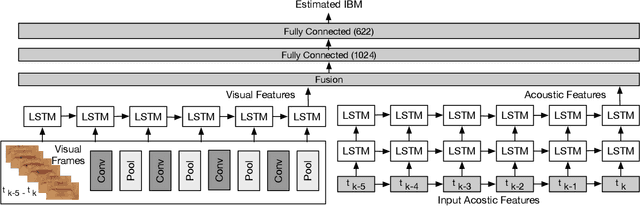
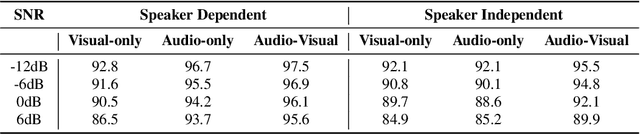
Human auditory cortex excels at selectively suppressing background noise to focus on a target speaker. The process of selective attention in the brain is known to contextually exploit the available audio and visual cues to better focus on target speaker while filtering out other noises. In this study, we propose a novel deep neural network (DNN) based audiovisual (AV) mask estimation model. The proposed AV mask estimation model contextually integrates the temporal dynamics of both audio and noise-immune visual features for improved mask estimation and speech separation. For optimal AV features extraction and ideal binary mask (IBM) estimation, a hybrid DNN architecture is exploited to leverages the complementary strengths of a stacked long short term memory (LSTM) and convolution LSTM network. The comparative simulation results in terms of speech quality and intelligibility demonstrate significant performance improvement of our proposed AV mask estimation model as compared to audio-only and visual-only mask estimation approaches for both speaker dependent and independent scenarios.