 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Feature Grouping as a Stochastic Regularizer for High-Dimensional Noisy Data
Paper and Code
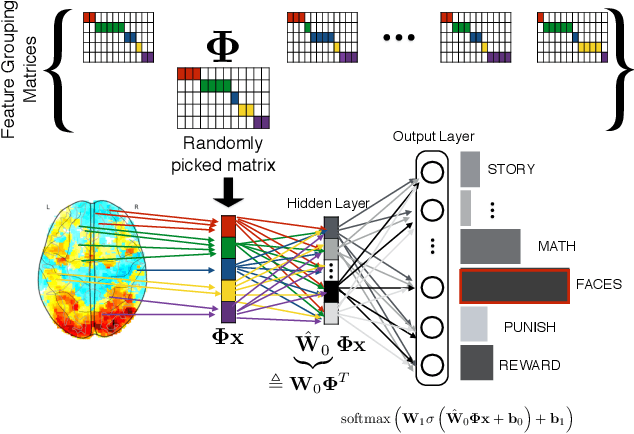
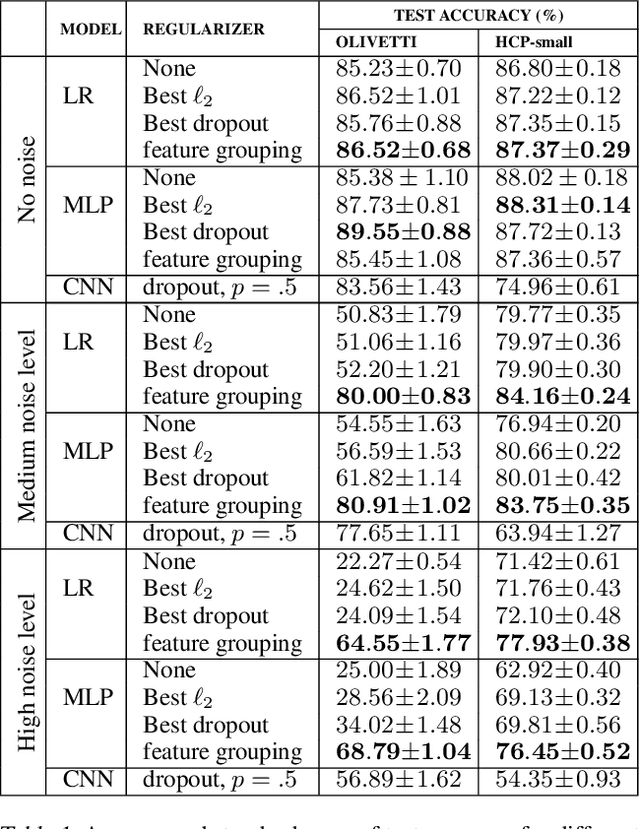
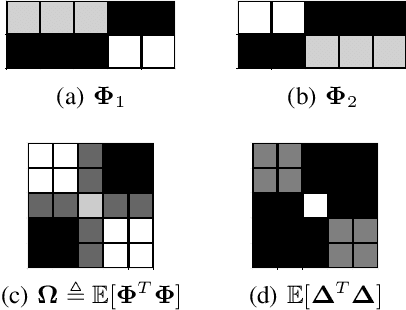

The use of complex models --with many parameters-- is challenging with high-dimensional small-sample problems: indeed, they face rapid overfitting. Such situations are common when data collection is expensive, as in neuroscience, biology, or geology. Dedicated regularization can be crafted to tame overfit, typically via structured penalties. But rich penalties require mathematical expertise and entail large computational costs. Stochastic regularizers such as dropout are easier to implement: they prevent overfitting by random perturbations. Used inside a stochastic optimizer, they come with little additional cost. We propose a structured stochastic regularization that relies on feature grouping. Using a fast clustering algorithm, we define a family of groups of features that capture feature covariations. We then randomly select these groups inside a stochastic gradient descent loop. This procedure acts as a structured regularizer for high-dimensional correlated data without additional computational cost and it has a denoising effect. We demonstrate the performance of our approach for logistic regression both on a sample-limited face image dataset with varying additive noise and on a typical high-dimensional learning problem, brain image classification.