 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Robust Feature Extraction for Rapid Low Resource ASR Development
Paper and Code
Sep 30, 2018
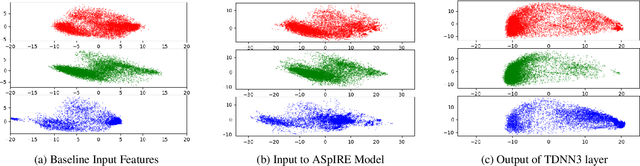

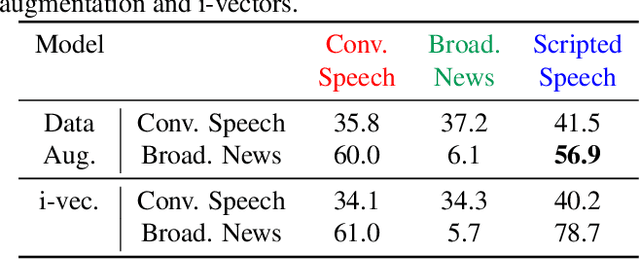
Developing a practical speech recognizer for a low resource language is challenging, not only because of the (potentially unknown) properties of the language, but also because test data may not be from the same domain as the available training data. In this paper, we focus on the latter challenge, i.e. domain mismatch, for systems trained using a sequence-based criterion. We demonstrate the effectiveness of using a pre-trained English recognizer, which is robust to such mismatched conditions, as a domain normalizing feature extractor on a low resource language. In our example, we use Turkish Conversational Speech and Broadcast News data. This enables rapid development of speech recognizers for new languages which can easily adapt to any domain. Testing in various cross-domain scenarios, we achieve relative improvements of around 25% in phoneme error rate, with improvements being around 50% for some domains.