 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning Approach to Target Tracking in a Camera Network
Paper and Code
Jul 26, 2018
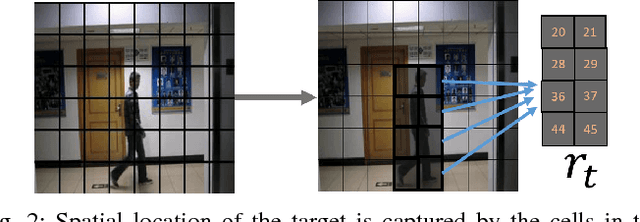
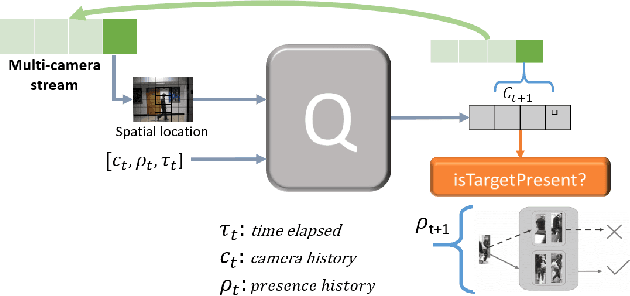
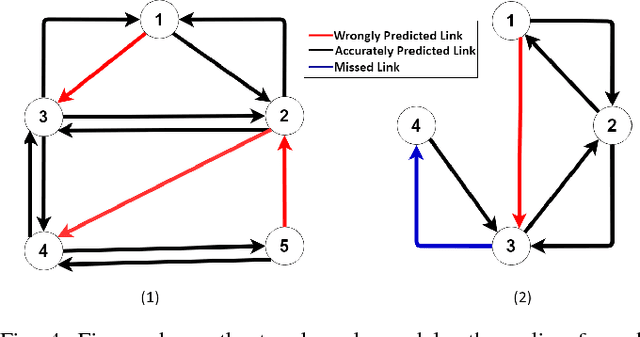
Target tracking in a camera network is an important task for surveillance and scene understanding. The task is challenging due to disjoint views and illumination variation in different cameras. In this direction, many graph-based methods were proposed using appearance-based features. However, the appearance information fades with high illumination variation in the different camera FOVs. We, in this paper, use spatial and temporal information as the state of the target to learn a policy that predicts the next camera given the current state. The policy is trained using Q-learning and it does not assume any information about the topology of the camera network. We will show that the policy learns the camera network topology. We demonstrate the performance of the proposed method on the NLPR MCT dataset.