 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Deep Multi-modal Learning Based on Gated Information Fusion Network
Paper and Code
Nov 02, 2018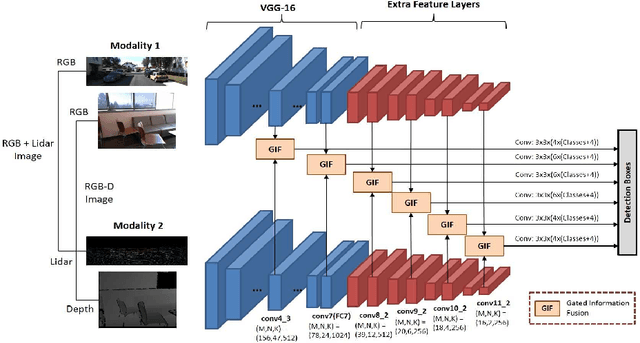

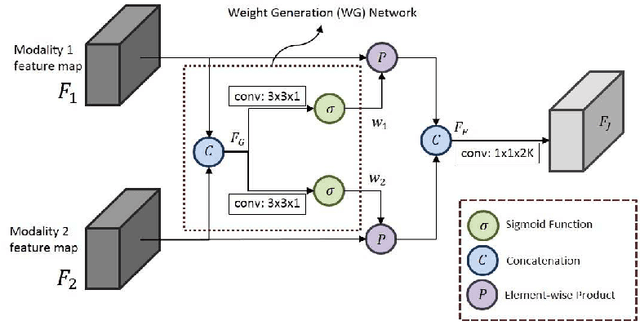

The goal of multi-modal learning is to use complimentary information on the relevant task provided by the multiple modalities to achieve reliable and robust performance. Recently, deep learning has led significant improvement in multi-modal learning by allowing for the information fusion in the intermediate feature levels. This paper addresses a problem of designing robust deep multi-modal learning architecture in the presence of imperfect modalities. We introduce deep fusion architecture for object detection which processes each modality using the separate convolutional neural network (CNN) and constructs the joint feature map by combining the intermediate features from the CNNs. In order to facilitate the robustness to the degraded modalities, we employ the gated information fusion (GIF) network which weights the contribution from each modality according to the input feature maps to be fused. The weights are determined through the convolutional layers followed by a sigmoid function and trained along with the information fusion network in an end-to-end fashion. Our experiments show that the proposed GIF network offers the additional architectural flexibility to achieve robust performance in handling some degraded modalities, and show a significant performance improvement based on Single Shot Detector (SSD) for KITTI dataset using the proposed fusion network and data augmentation schemes.