 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards more Reliable Transfer Learning
Paper and Code
Jul 06, 2018
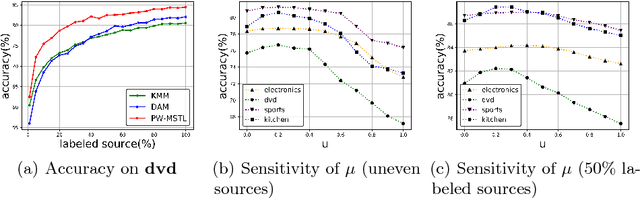
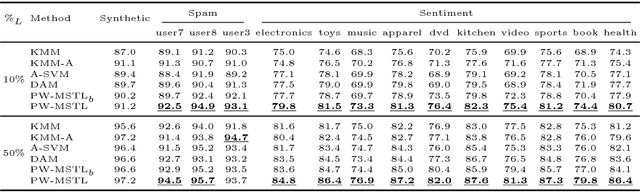
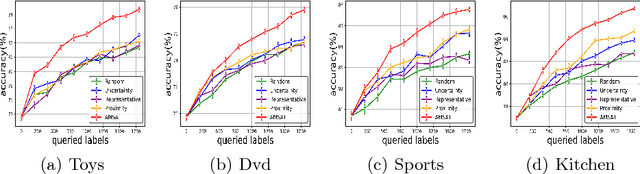
Multi-source transfer learning has been proven effective when within-target labeled data is scarce. Previous work focuses primarily on exploiting domain similarities and assumes that source domains are richly or at least comparably labeled. While this strong assumption is never true in practice, this paper relaxes it and addresses challenges related to sources with diverse labeling volume and diverse reliability. The first challenge is combining domain similarity and source reliability by proposing a new transfer learning method that utilizes both source-target similarities and inter-source relationships. The second challenge involves pool-based active learning where the oracle is only available in source domains, resulting in an integrated active transfer learning framework that incorporates distribution matching and uncertainty sampling. Extensive experiments on synthetic and two real-world datasets clearly demonstrate the superiority of our proposed methods over several baselines including state-of-the-art transfer learning methods.