 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spatial and Temporal Features Mixture Model with Body Parts for Video-based Person Re-Identification
Paper and Code
Jul 03, 2018

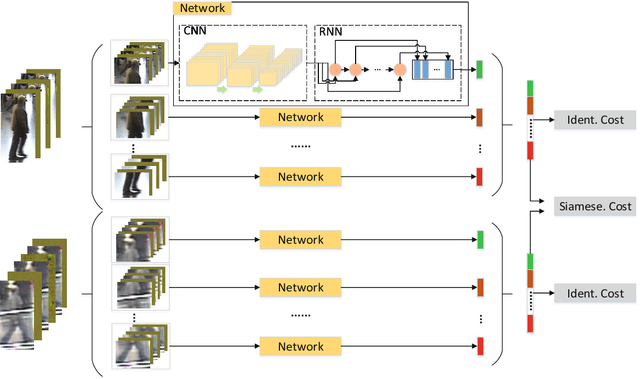
The video-based person re-identification is to recognize a person under different cameras, which is a crucial task applied in visual surveillance system. Most previous methods mainly focused on the feature of full body in the frame. In this paper we propose a novel Spatial and Temporal Features Mixture Model (STFMM) based on convolutional neural network (CNN) and recurrent neural network (RNN), in which the human body is split into $N$ parts in horizontal direction so that we can obtain more specific features. The proposed method skillfully integrates features of each part to achieve more expressive representation of each person. We first split the video sequence into $N$ part sequences which include the information of head, waist, legs and so on. Then the features are extracted by STFMM whose $2N$ inputs are obtained from the developed Siamese network, and these features are combined into a discriminative representation for one person. Experiments are conducted on the iLIDS-VID and PRID-2011 datasets. The results demonstrate that our approach outperforms existing methods for video-based person re-identification. It achieves a rank-1 CMC accuracy of 74\% on the iLIDS-VID dataset, exceeding the the most recently developed method ASTPN by 12\%. For the cross-data testing, our method achieves a rank-1 CMC accuracy of 48\% exceeding the ASTPN method by 18\%, which shows that our model has significant stability.