 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight-importance sparse training in keyword spotting
Paper and Code
Jul 09, 2018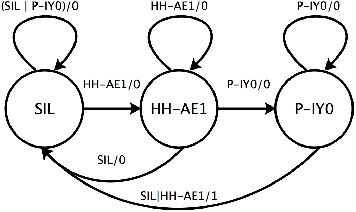
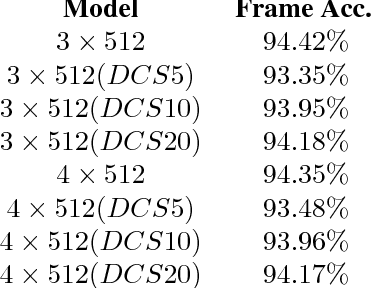
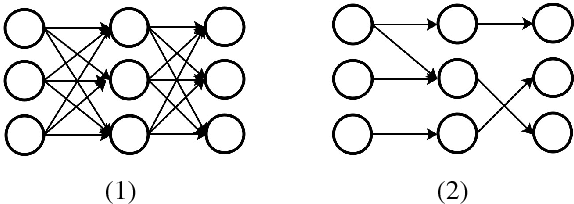
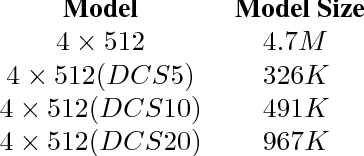
Large size models are implemented in recently ASR system to deal with complex speech recognition problems. The num- ber of parameters in these models makes them hard to deploy, especially on some resource-short devices such as car tablet. Besides this, at most of time, ASR system is used to deal with real-time problem such as keyword spotting (KWS). It is contradictory to the fact that large model requires long com- putation time. To deal with this problem, we apply some sparse algo- rithms to reduces number of parameters in some widely used models, Deep Neural Network (DNN) KWS, which requires real short computation time. We can prune more than 90 % even 95% of parameters in the model with tiny effect decline. And the sparse model performs better than baseline models which has same order number of parameters. Besides this, sparse algorithm can lead us to find rational model size au- tomatically for certain problem without concerning choosing an original model size.