 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Directed Fairness Testing
Paper and Code
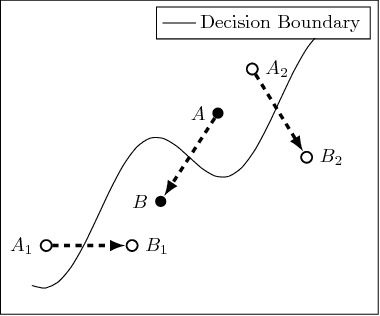

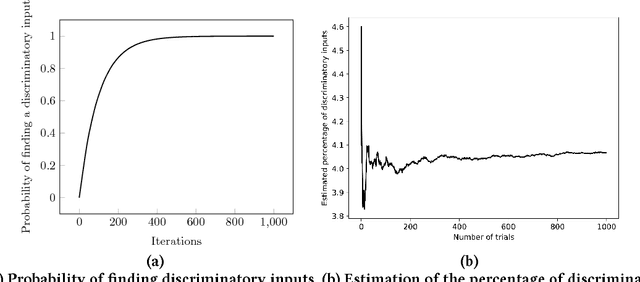
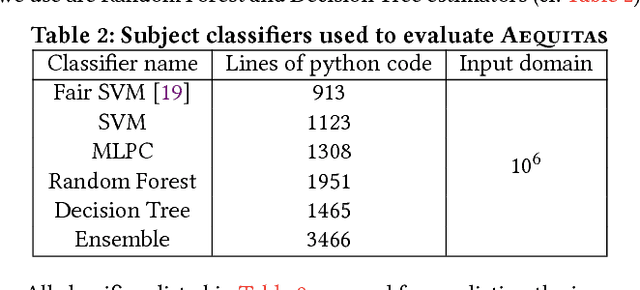
Fairness is a critical trait in decision making. As machine-learning models are increasingly being used in sensitive application domains (e.g. education and employment) for decision making, it is crucial that the decisions computed by such models are free of unintended bias. But how can we automatically validate the fairness of arbitrary machine-learning models? For a given machine-learning model and a set of sensitive input parameters, our AEQUITAS approach automatically discovers discriminatory inputs that highlight fairness violation. At the core of AEQUITAS are three novel strategies to employ probabilistic search over the input space with the objective of uncovering fairness violation. Our AEQUITAS approach leverages inherent robustness property in common machine-learning models to design and implement scalable test generation methodologies. An appealing feature of our generated test inputs is that they can be systematically added to the training set of the underlying model and improve its fairness. To this end, we design a fully automated module that guarantees to improve the fairness of the underlying model. We implemented AEQUITAS and we have evaluated it on six state-of-the-art classifiers, including a classifier that was designed with fairness constraints. We show that AEQUITAS effectively generates inputs to uncover fairness violation in all the subject classifiers and systematically improves the fairness of the respective models using the generated test inputs. In our evaluation, AEQUITAS generates up to 70% discriminatory inputs (w.r.t. the total number of inputs generated) and leverages these inputs to improve the fairness up to 94%.