 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples in Deep Learning: Characterization and Divergence
Paper and Code
Oct 29, 2018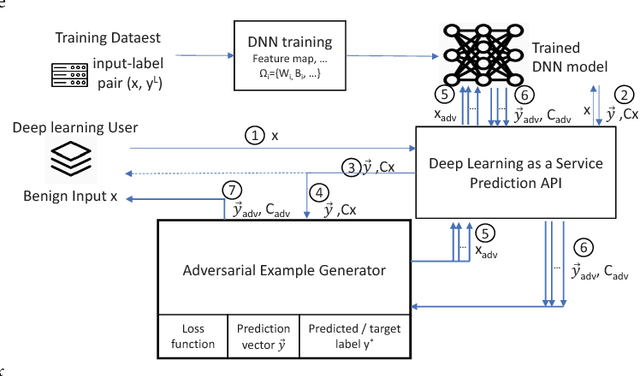

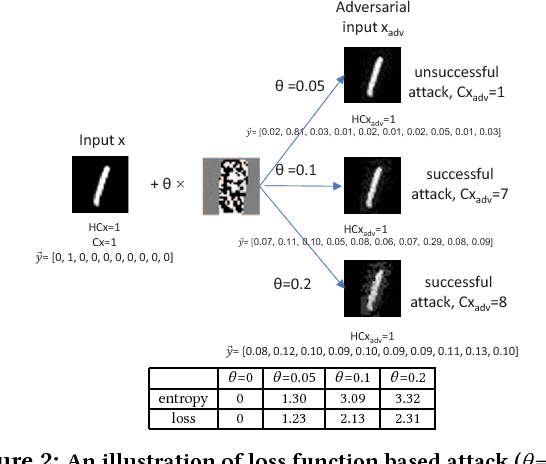
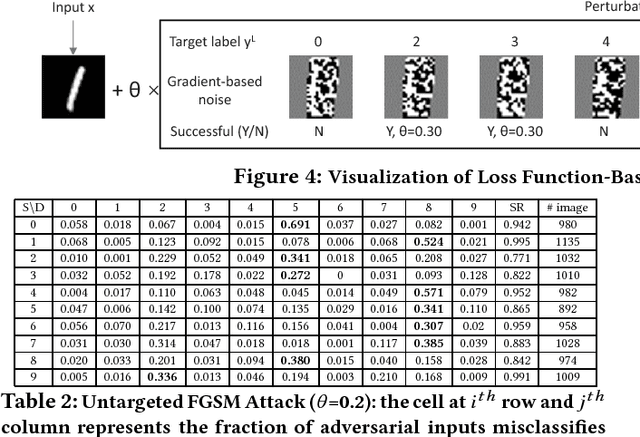
The burgeoning success of deep learning has raised the security and privacy concerns as more and more tasks are accompanied with sensitive data. Adversarial attacks in deep learning have emerged as one of the dominating security threat to a range of mission-critical deep learning systems and applications. This paper takes a holistic and principled approach to perform statistical characterization of adversarial examples in deep learning. We provide a general formulation of adversarial examples and elaborate on the basic principle for adversarial attack algorithm design. We introduce easy and hard categorization of adversarial attacks to analyze the effectiveness of adversarial examples in terms of attack success rate, degree of change in adversarial perturbation, average entropy of prediction qualities, and fraction of adversarial examples that lead to successful attacks. We conduct extensive experimental study on adversarial behavior in easy and hard attacks under deep learning models with different hyperparameters and different deep learning frameworks. We show that the same adversarial attack behaves differently under different hyperparameters and across different frameworks due to the different features learned under different deep learning model training process. Our statistical characterization with strong empirical evidence provides a transformative enlightenment on mitigation strategies towards effective countermeasures against present and future adversarial attacks.