Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attentive Neural Collaborative Filtering
Paper and Code
Jul 19, 2018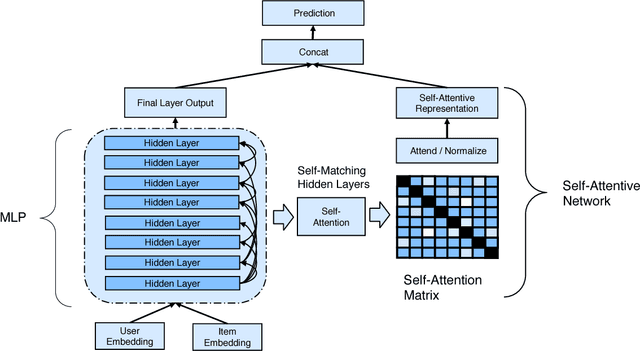
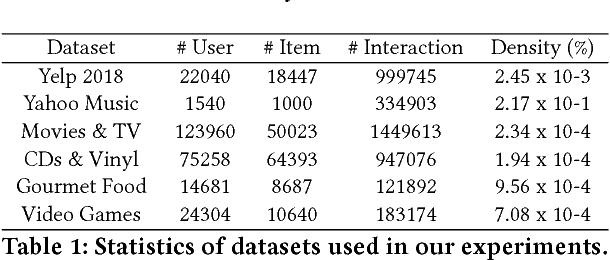
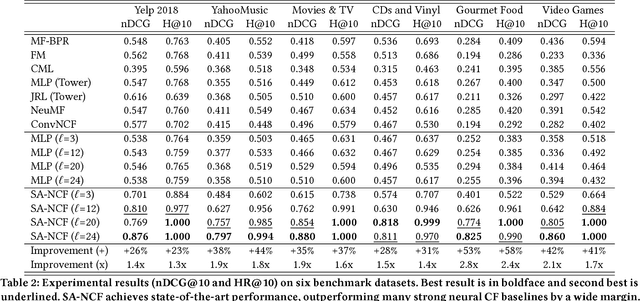
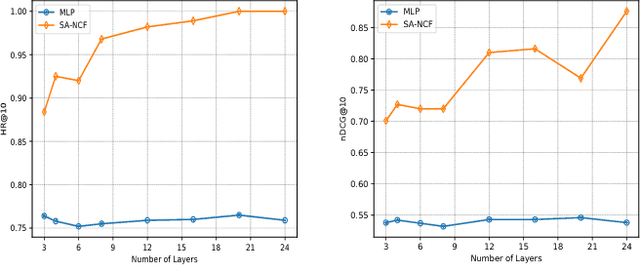
This paper has been withdrawn as we discovered a bug in our tensorflow implementation that involved accidental mixing of vectors across batches. This lead to different inference results given different batch sizes which is completely strange. The performance scores still remain the same but we concluded that it was not the self-attention that contributed to the performance. We are withdrawing the paper because this renders the main claim of the paper false. Thanks to Guan Xinyu from NUS for discovering this issue in our previously open source code.
* We discovered a bug in our tensorflow implementation that involved
accidental mixing of vectors across batches, rendering the main claim of the
paper incorrect. We are withdrawing this paper until we find out why
View paper on