 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning kernels that adapt to GPU
Paper and Code
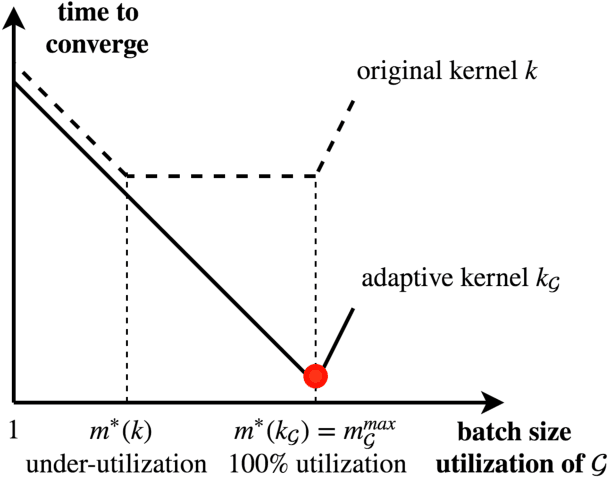
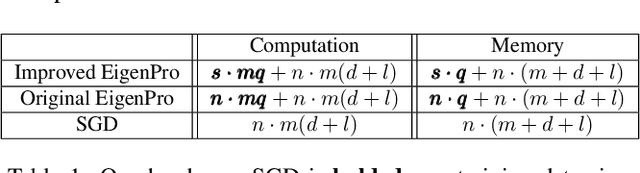
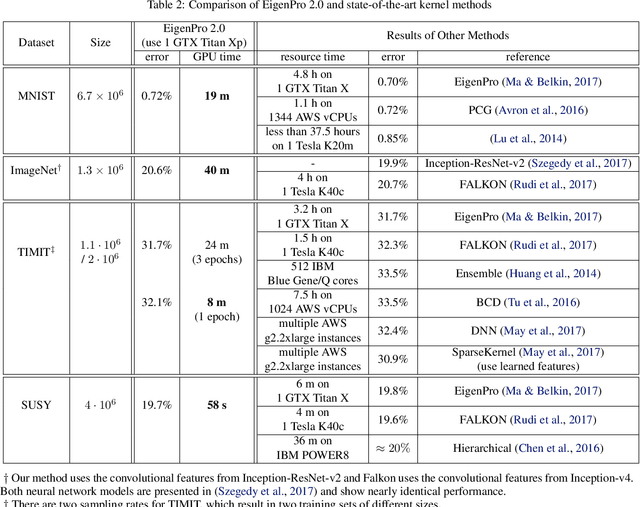
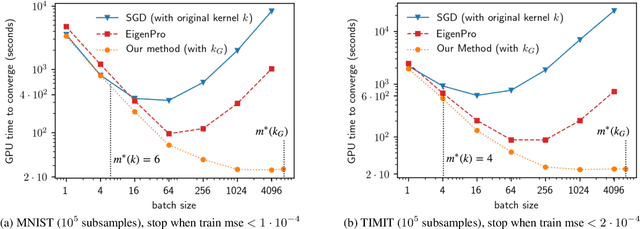
In this work we develop a framework for kernel machines that are efficient, accurate and are adaptive to modern parallel hardware, such as GPU. Our main innovation is in constructing kernel machines that output solutions mathematically equivalent to those obtained using standard kernels, yet capable of fully utilizing the available computing power of a parallel computational resource. Such utilization is key to strong performance as much of the computational resource capability is wasted by the standard iterative methods. Our approach is based on the idea of interpolation, using the significant empirical evidence that methods achieving near-zero training error show excellent test results. In this work we show how the mathematical and conceptual simplicity of optimization in the interpolation regime can be harnessed to design kernels and automatically choose parameters adaptive to computational resources. The resulting algorithm, which we call \textit{EigenPro 2.0}, is accurate, principled and very fast. For example, using a single Titan XP GPU, training on ImageNet with $1.3\times 10^6$ data points and $1000$ labels takes under an hour, while smaller datasets, such as MNIST, take seconds. As the parameters are chosen analytically, based on the theoretical bounds, little tuning beyond selecting the kernel and kernel parameter is needed, further facilitating the practical use of these methods.