 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfless Sequential Learning
Paper and Code
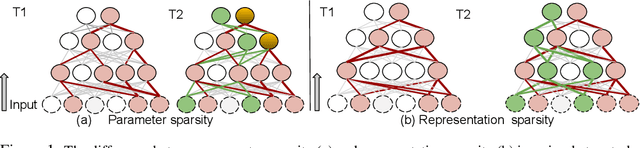
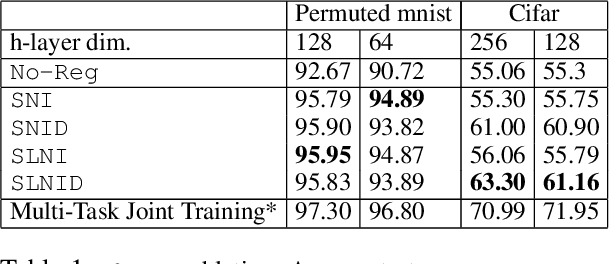
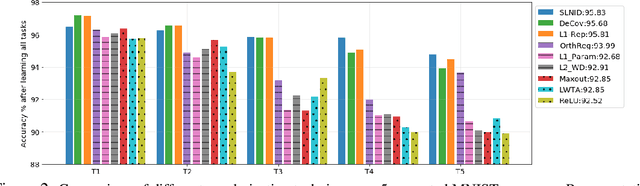

Sequential learning studies the problem of learning tasks in a sequence with access restricted to only the data of the current task. In this paper we look at a scenario with a fixed model capacity, and postulate that the learning process should not be selfish, i.e. it should account for future tasks to be added and %therefore aim at utilizing a minimum number of neurons, thus leave enough capacity for them. To achieve Selfless Sequential Learning} we study different regularization strategies and activation functions that could lead to less interference between the different tasks. We find that learning a sparse representation is more beneficial for sequential learning than encouraging parameter sparsity. In particular, we propose a novel regularizer, that encourages representation sparsity by means of neural inhibition. It results in few active neurons which in turn leaves more free neurons to be utilized by upcoming tasks. As suppressing all other neurons in a layer can be too drastic, especially for complex tasks requiring strong representations, our regularizer only inhibits other neurons in a local neighbourhood, inspired by inhibition processes in the brain. We combine our novel regularizer, SLNI, with state-of-the-art sequential learning methods that penalize changes to important previously learned parts of the network. We show that our new regularizer leads to increased sparsity which translates in consistent performance improvement %over alternative regularizers we studied on diverse datasets.