 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCAS: Pruning Channels with Attention Statistics
Paper and Code
Jun 14, 2018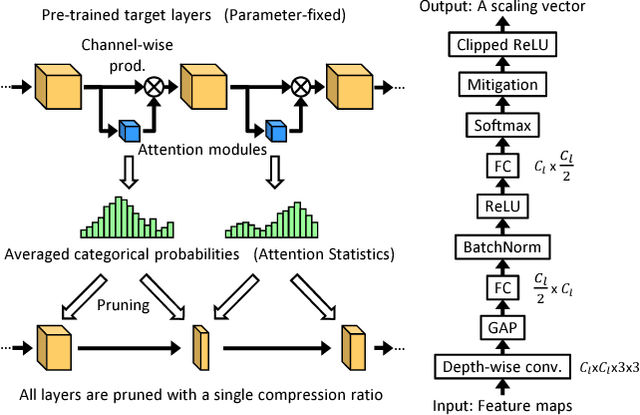
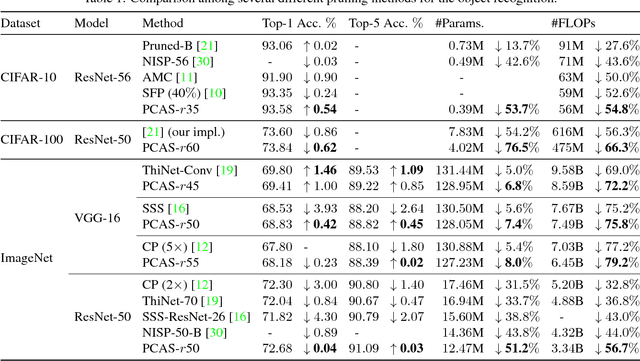

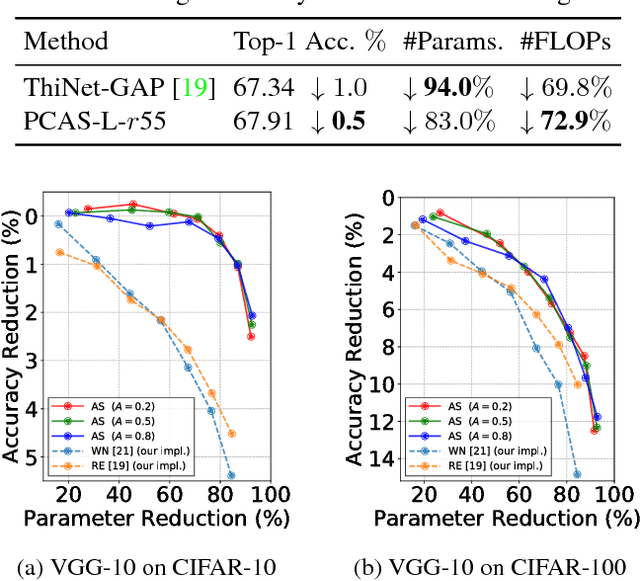
To implement deep neural networks on small embedded devices, conventional techniques use channel pruning looking considering manual compression rate per layer to reduce parameters. Besides it is difficult to consider the relationships between layers and it takes a lot of time for deeper models. For addressing these issues, we propose a new channel pruning technique based on attention that can evaluate the importance of channels. We improved the method with the criterion to allow the automatic channel selection using a single compression rate for the entire model. Experimental results showed that a parameter reduction of 90.8% and FLOPs reduction of 79.4% was achieved with an accuracy degradation of around 1% for the compressed ResNet-50 model on the CIFAR-10 benchmark.