 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTotalFM: An Organ-Separated Framework for 3D-CT Vision Foundation Models
Jan 01, 2026While foundation models in radiology are expected to be applied to various clinical tasks, computational cost constraints remain a major challenge when training on 3D-CT volumetric data. In this study, we propose TotalFM, a radiological foundation model that efficiently learns the correspondence between 3D-CT images and linguistic expressions based on the concept of organ separation, utilizing a large-scale dataset of 140,000 series. By automating the creation of organ volume and finding-sentence pairs through segmentation techniques and Large Language Model (LLM)-based radiology report processing, and by combining self-supervised pre-training via VideoMAE with contrastive learning using volume-text pairs, we aimed to balance computational efficiency and representation capability. In zero-shot organ-wise lesion classification tasks, the proposed model achieved higher F1 scores in 83% (5/6) of organs compared to CT-CLIP and 64% (9/14) of organs compared to Merlin. These results suggest that the proposed model exhibits high generalization performance in a clinical evaluation setting using actual radiology report sentences. Furthermore, in zero-shot finding-wise lesion classification tasks, our model achieved a higher AUROC in 83% (25/30) of finding categories compared to Merlin. We also confirmed performance comparable to existing Vision-Language Models (VLMs) in radiology report generation tasks. Our results demonstrate that the organ-separated learning framework can serve as a realistic and effective design guideline for the practical implementation of 3D-CT foundation models.
Learnable Companding Quantization for Accurate Low-bit Neural Networks
Mar 12, 2021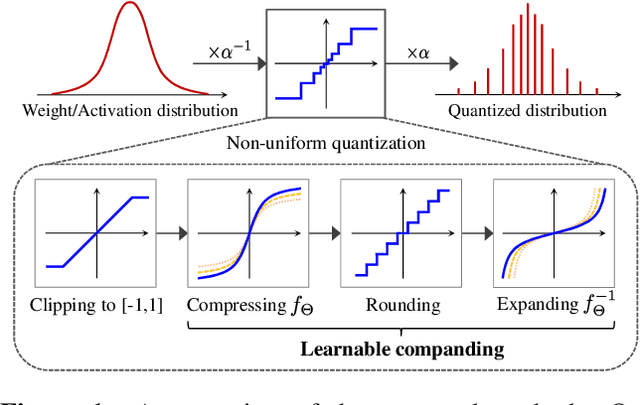
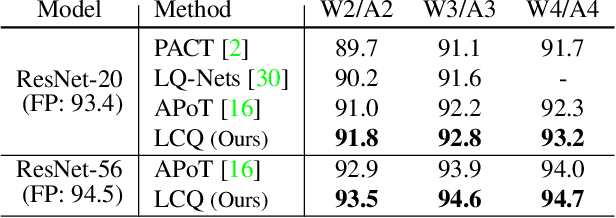
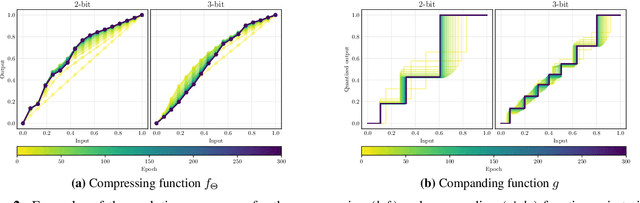
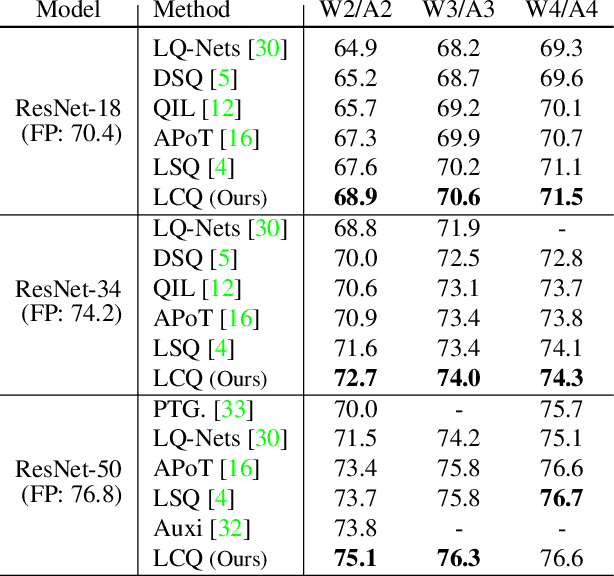
Quantizing deep neural networks is an effective method for reducing memory consumption and improving inference speed, and is thus useful for implementation in resource-constrained devices. However, it is still hard for extremely low-bit models to achieve accuracy comparable with that of full-precision models. To address this issue, we propose learnable companding quantization (LCQ) as a novel non-uniform quantization method for 2-, 3-, and 4-bit models. LCQ jointly optimizes model weights and learnable companding functions that can flexibly and non-uniformly control the quantization levels of weights and activations. We also present a new weight normalization technique that allows more stable training for quantization. Experimental results show that LCQ outperforms conventional state-of-the-art methods and narrows the gap between quantized and full-precision models for image classification and object detection tasks. Notably, the 2-bit ResNet-50 model on ImageNet achieves top-1 accuracy of 75.1% and reduces the gap to 1.7%, allowing LCQ to further exploit the potential of non-uniform quantization.
PCAS: Pruning Channels with Attention Statistics
Jun 14, 2018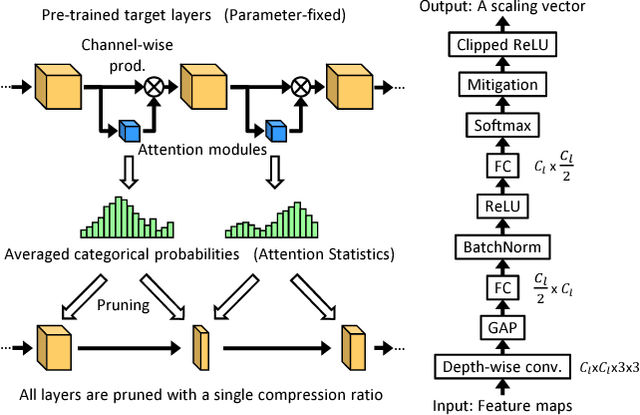
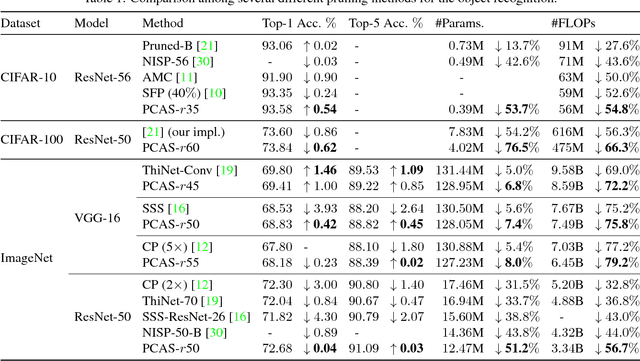

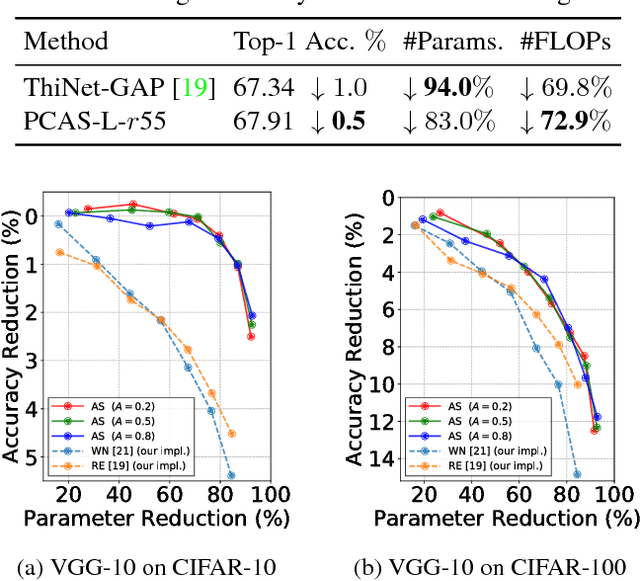
To implement deep neural networks on small embedded devices, conventional techniques use channel pruning looking considering manual compression rate per layer to reduce parameters. Besides it is difficult to consider the relationships between layers and it takes a lot of time for deeper models. For addressing these issues, we propose a new channel pruning technique based on attention that can evaluate the importance of channels. We improved the method with the criterion to allow the automatic channel selection using a single compression rate for the entire model. Experimental results showed that a parameter reduction of 90.8% and FLOPs reduction of 79.4% was achieved with an accuracy degradation of around 1% for the compressed ResNet-50 model on the CIFAR-10 benchmark.