 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional sparse coding for capturing high speed video content
Paper and Code
Jun 13, 2018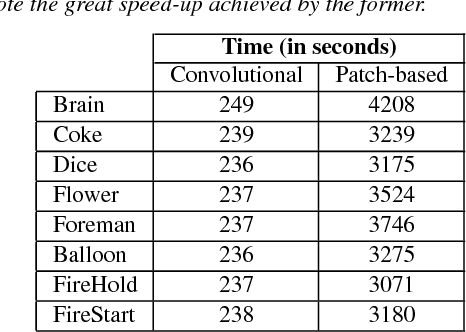
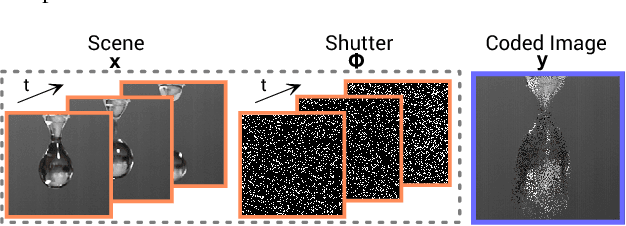

Video capture is limited by the trade-off between spatial and temporal resolution: when capturing videos of high temporal resolution, the spatial resolution decreases due to bandwidth limitations in the capture system. Achieving both high spatial and temporal resolution is only possible with highly specialized and very expensive hardware, and even then the same basic trade-off remains. The recent introduction of compressive sensing and sparse reconstruction techniques allows for the capture of single-shot high-speed video, by coding the temporal information in a single frame, and then reconstructing the full video sequence from this single coded image and a trained dictionary of image patches. In this paper, we first analyze this approach, and find insights that help improve the quality of the reconstructed videos. We then introduce a novel technique, based on convolutional sparse coding (CSC), and show how it outperforms the state-of-the-art, patch-based approach in terms of flexibility and efficiency, due to the convolutional nature of its filter banks. The key idea for CSC high-speed video acquisition is extending the basic formulation by imposing an additional constraint in the temporal dimension, which enforces sparsity of the first-order derivatives over time.