 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Planning Shape on Dyna-style Planning in High-dimensional State Spaces
Paper and Code
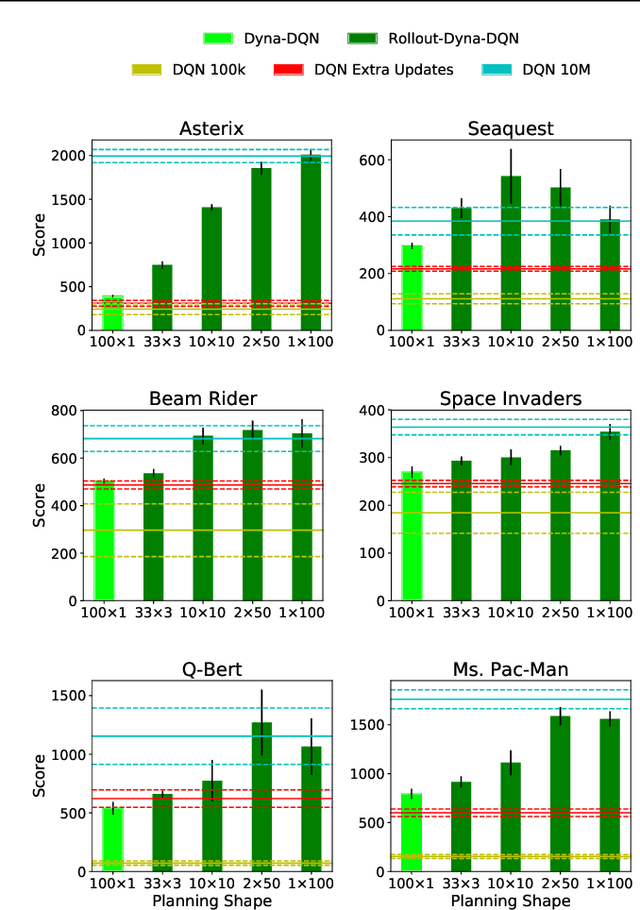
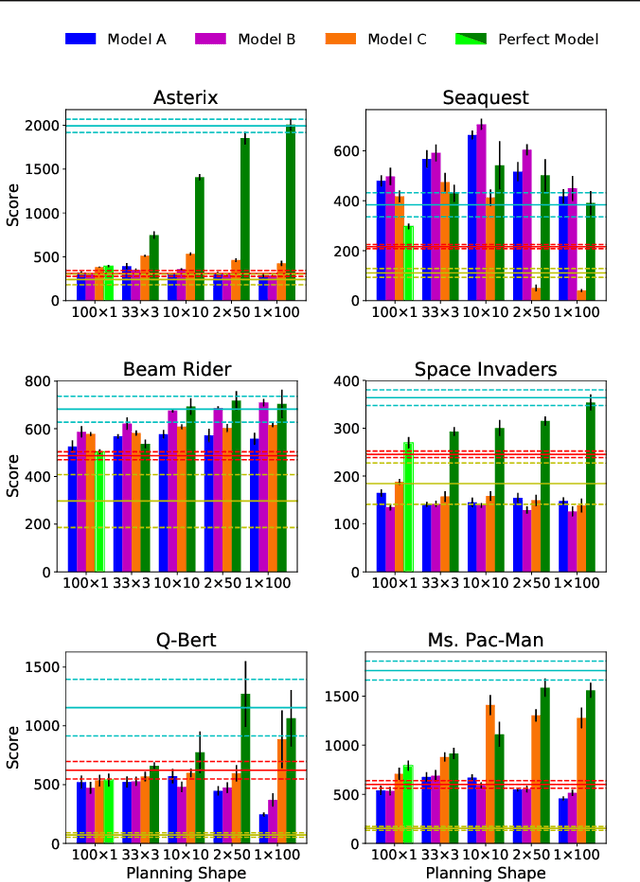
Dyna is an architecture for reinforcement learning agents that interleaves planning, acting, and learning in an online setting. This architecture aims to make fuller use of limited experience to achieve better performance with fewer environmental interactions. Dyna has been well studied in problems with a tabular representation of states, and has also been extended to some settings with larger state spaces that require function approximation. However, little work has studied Dyna in environments with high-dimensional state spaces like images. In Dyna, the environment model is typically used to generate one-step transitions from selected start states. We applied one-step Dyna to several games from the Arcade Learning Environment and found that the model-based updates offered surprisingly little benefit, even with a perfect model. However, when the model was used to generate longer trajectories of simulated experience, performance improved dramatically. This observation also holds when using a model that is learned from experience; even though the learned model is flawed, it can still be used to accelerate learning.