 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdrop: Stochastic Backpropagation
Paper and Code
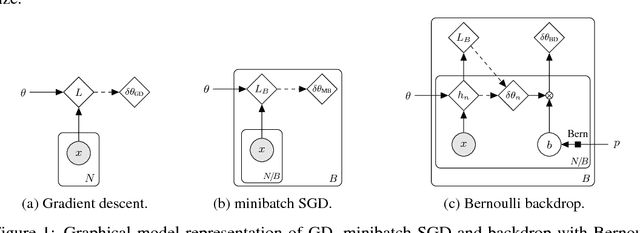
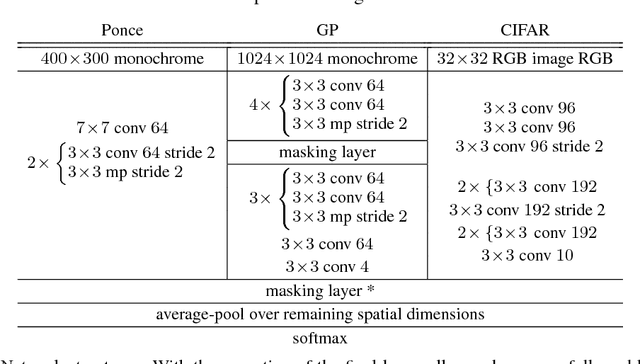
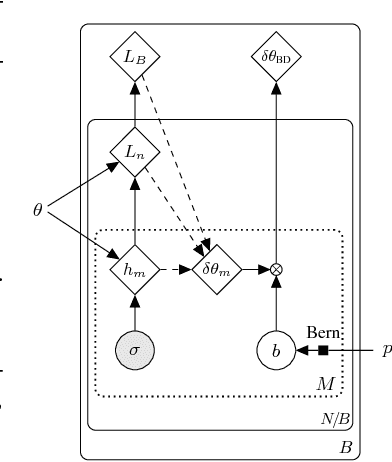
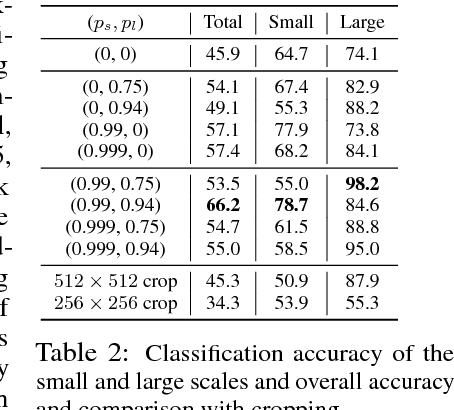
We introduce backdrop, a flexible and simple-to-implement method, intuitively described as dropout acting only along the backpropagation pipeline. Backdrop is implemented via one or more masking layers which are inserted at specific points along the network. Each backdrop masking layer acts as the identity in the forward pass, but randomly masks parts of the backward gradient propagation. Intuitively, inserting a backdrop layer after any convolutional layer leads to stochastic gradients corresponding to features of that scale. Therefore, backdrop is well suited for problems in which the data have a multi-scale, hierarchical structure. Backdrop can also be applied to problems with non-decomposable loss functions where standard SGD methods are not well suited. We perform a number of experiments and demonstrate that backdrop leads to significant improvements in generalization.