 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-vehicle Flocking Control with Deep Deterministic Policy Gradient Method
Paper and Code
Jun 01, 2018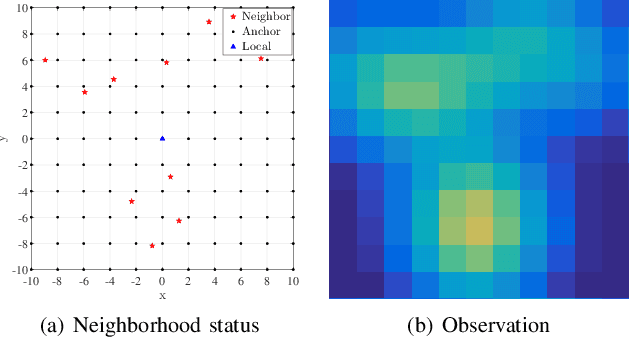
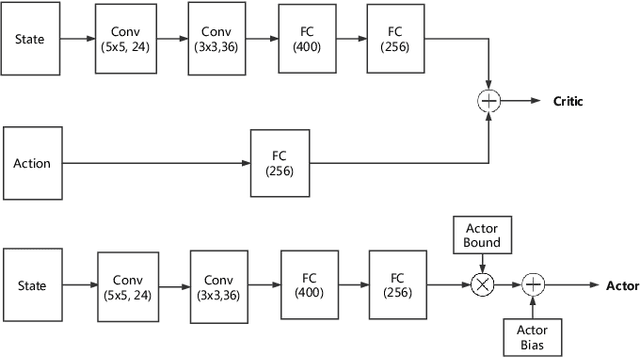
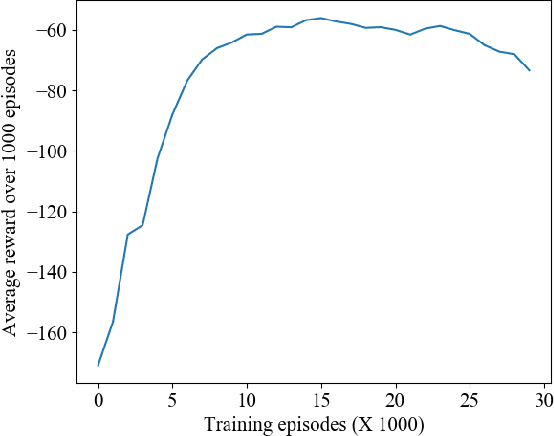
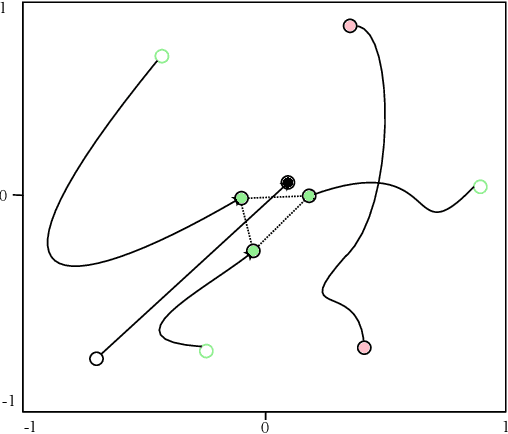
Flocking control has been studied extensively along with the wide application of multi-vehicle systems. In this paper the Multi-vehicles System (MVS) flocking control with collision avoidance and communication preserving is considered based on the deep reinforcement learning framework. Specifically the deep deterministic policy gradient (DDPG) with centralized training and distributed execution process is implemented to obtain the flocking control policy. First, to avoid the dynamically changed observation of state, a three layers tensor based representation of the observation is used so that the state remains constant although the observation dimension is changing. A reward function is designed to guide the way-points tracking, collision avoidance and communication preserving. The reward function is augmented by introducing the local reward function of neighbors. Finally, a centralized training process which trains the shared policy based on common training set among all agents. The proposed method is tested under simulated scenarios with different setup.