 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Large-Scale Data Acquisition via Crowdsourcing for Crosswalk Classification: A Deep Learning Approach
Paper and Code
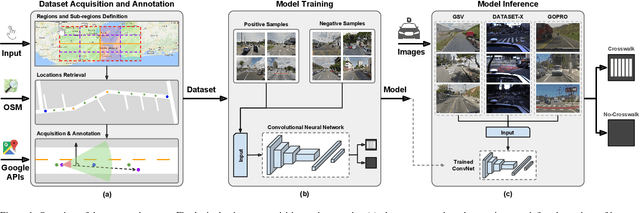
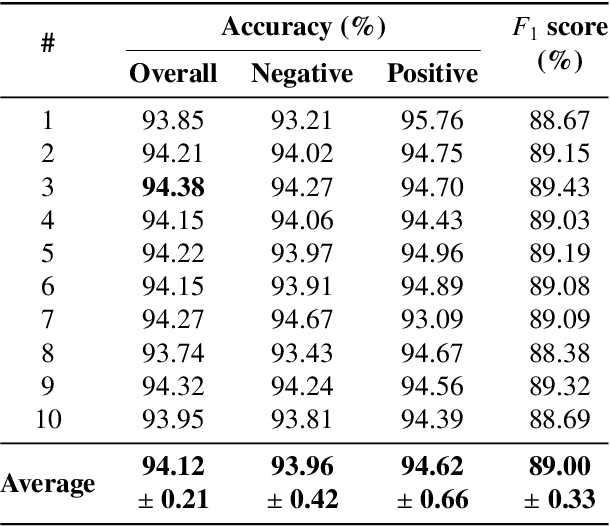
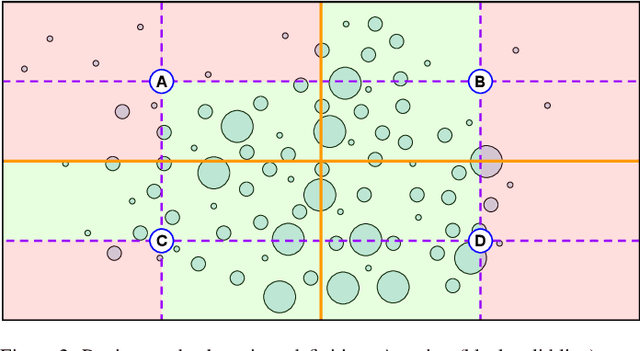
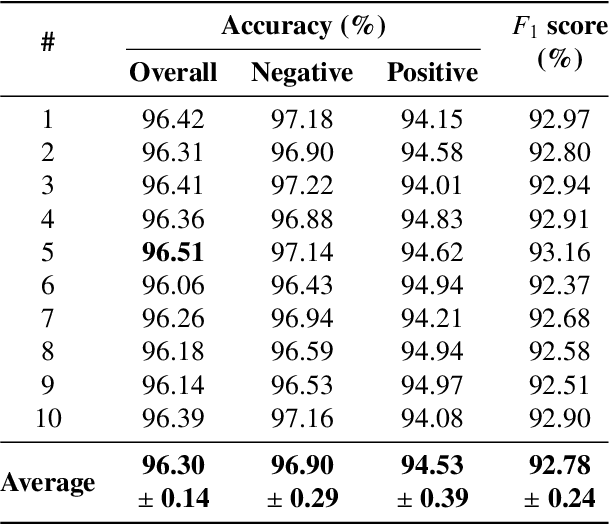
Correctly identifying crosswalks is an essential task for the driving activity and mobility autonomy. Many crosswalk classification, detection and localization systems have been proposed in the literature over the years. These systems use different perspectives to tackle the crosswalk classification problem: satellite imagery, cockpit view (from the top of a car or behind the windshield), and pedestrian perspective. Most of the works in the literature are designed and evaluated using small and local datasets, i.e. datasets that present low diversity. Scaling to large datasets imposes a challenge for the annotation procedure. Moreover, there is still need for cross-database experiments in the literature because it is usually hard to collect the data in the same place and conditions of the final application. In this paper, we present a crosswalk classification system based on deep learning. For that, crowdsourcing platforms, such as OpenStreetMap and Google Street View, are exploited to enable automatic training via automatic acquisition and annotation of a large-scale database. Additionally, this work proposes a comparison study of models trained using fully-automatic data acquisition and annotation against models that were partially annotated. Cross-database experiments were also included in the experimentation to show that the proposed methods enable use with real world applications. Our results show that the model trained on the fully-automatic database achieved high overall accuracy (94.12%), and that a statistically significant improvement (to 96.30%) can be achieved by manually annotating a specific part of the database. Finally, the results of the cross-database experiments show that both models are robust to the many variations of image and scenarios, presenting a consistent behavior.