 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically-informed distance and similarity measures for paraphrase plagiarism identification
Paper and Code
May 29, 2018

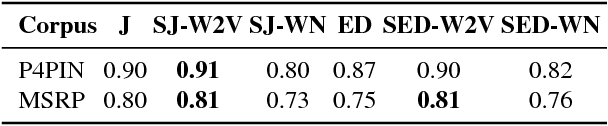
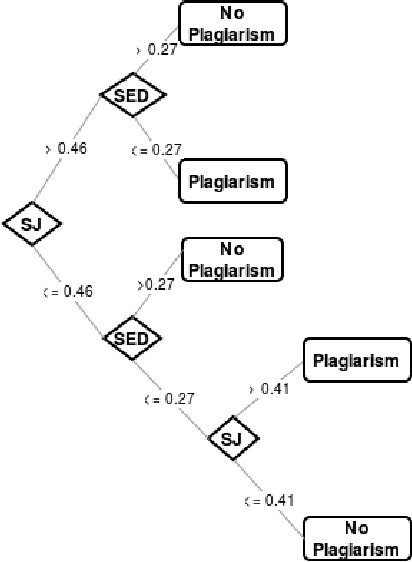
Paraphrase plagiarism identification represents a very complex task given that plagiarized texts are intentionally modified through several rewording techniques. Accordingly, this paper introduces two new measures for evaluating the relatedness of two given texts: a semantically-informed similarity measure and a semantically-informed edit distance. Both measures are able to extract semantic information from either an external resource or a distributed representation of words, resulting in informative features for training a supervised classifier for detecting paraphrase plagiarism. Obtained results indicate that the proposed metrics are consistently good in detecting different types of paraphrase plagiarism. In addition, results are very competitive against state-of-the art methods having the advantage of representing a much more simple but equally effective solution.