 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforcement Learning
Paper and Code
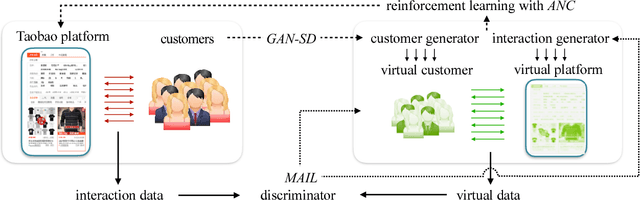
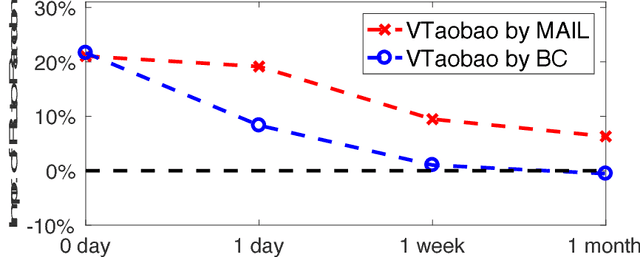
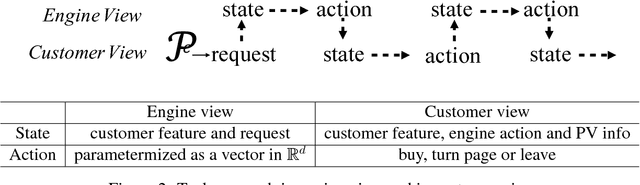

Applying reinforcement learning in physical-world tasks is extremely challenging. It is commonly infeasible to sample a large number of trials, as required by current reinforcement learning methods, in a physical environment. This paper reports our project on using reinforcement learning for better commodity search in Taobao, one of the largest online retail platforms and meanwhile a physical environment with a high sampling cost. Instead of training reinforcement learning in Taobao directly, we present our approach: first we build Virtual Taobao, a simulator learned from historical customer behavior data through the proposed GAN-SD (GAN for Simulating Distributions) and MAIL (multi-agent adversarial imitation learning), and then we train policies in Virtual Taobao with no physical costs in which ANC (Action Norm Constraint) strategy is proposed to reduce over-fitting. In experiments, Virtual Taobao is trained from hundreds of millions of customers' records, and its properties are compared with the real environment. The results disclose that Virtual Taobao faithfully recovers important properties of the real environment. We also show that the policies trained in Virtual Taobao can have significantly superior online performance to the traditional supervised approaches. We hope our work could shed some light on reinforcement learning applications in complex physical environments.