 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained-CNN losses forweakly supervised segmentation
Paper and Code
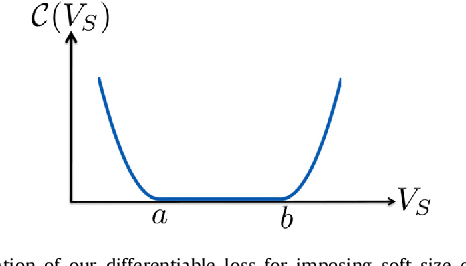
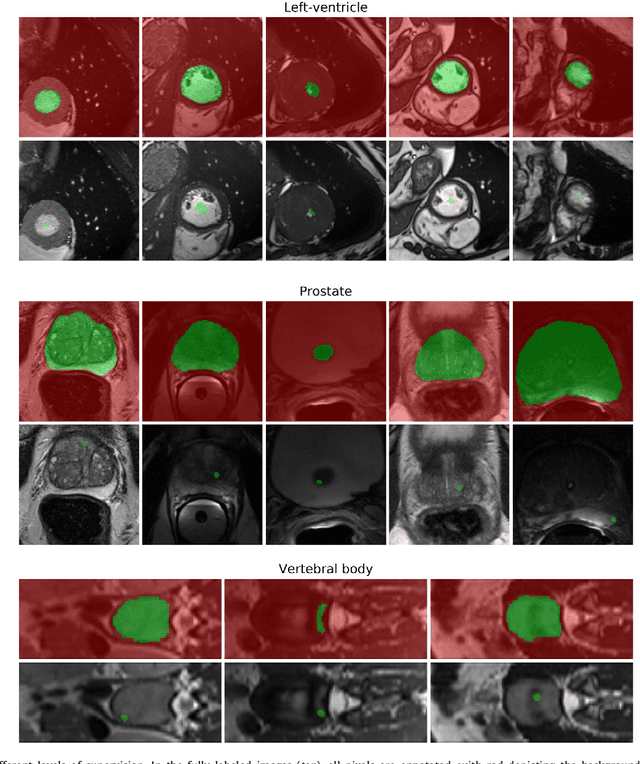
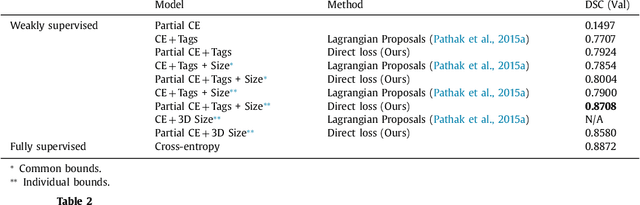
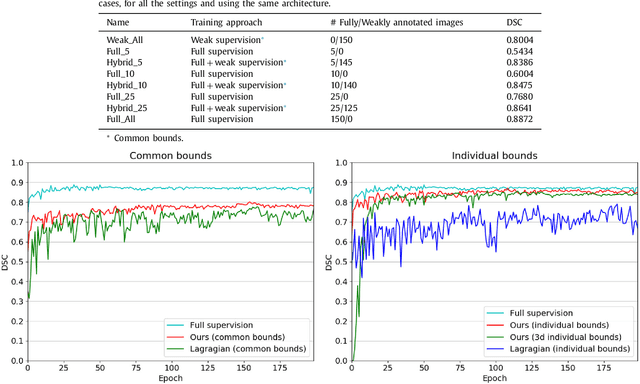
Weak supervision, e.g., in the form of partial labels or image tags, is currently attracting significant attention in CNN segmentation as it can mitigate the lack of full and laborious pixel/voxel annotations. Enforcing high-order (global) inequality constraints on the network output, for instance, on the size of the target region, can leverage unlabeled data, guiding training with domain-specific knowledge. Inequality constraints are very flexible because they do not assume exact prior knowledge. However,constrained Lagrangian dual optimization has been largely avoided in deep networks, mainly for computational tractability reasons.To the best of our knowledge, the method of Pathak et al. is the only prior work that addresses deep CNNs with linear constraints in weakly supervised segmentation. It uses the constraints to synthesize fully-labeled training masks (proposals)from weak labels, mimicking full supervision and facilitating dual optimization.We propose to introduce a differentiable term, which enforces inequality constraints directly in the loss function, avoiding expensive Lagrangian dual iterates and proposal generation. From constrained-optimization perspective, our simple approach is not optimal as there is no guarantee that the constraints are satisfied. However, surprisingly,it yields substantially better results than the proposal-based constrained CNNs, while reducing the computational demand for training.In the context of cardiac images, we reached a segmentation performance close to full supervision using a fraction (0.1%) of the full ground-truth labels and image-level tags.While our experiments focused on basic linear constraints such as the target-region size and image tags, our framework can be easily extended to other non-linear constraints.Therefore, it has the potential to close the gap between weakly and fully supervised learning in semantic image segmentation.