 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent CNN for 3D Gaze Estimation using Appearance and Shape Cues
Paper and Code
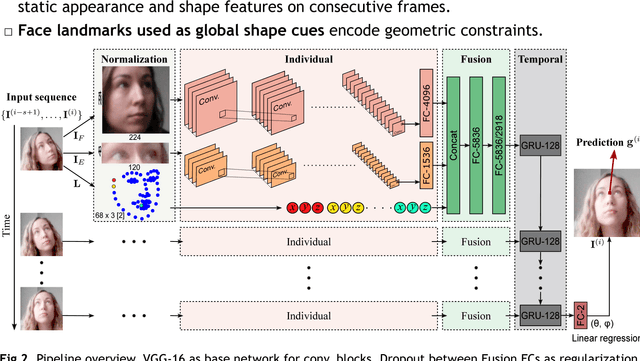

Gaze behavior is an important non-verbal cue in social signal processing and human-computer interaction. In this paper, we tackle the problem of person- and head pose-independent 3D gaze estimation from remote cameras, using a multi-modal recurrent convolutional neural network (CNN). We propose to combine face, eyes region, and face landmarks as individual streams in a CNN to estimate gaze in still images. Then, we exploit the dynamic nature of gaze by feeding the learned features of all the frames in a sequence to a many-to-one recurrent module that predicts the 3D gaze vector of the last frame. Our multi-modal static solution is evaluated on a wide range of head poses and gaze directions, achieving a significant improvement of 14.6% over the state of the art on EYEDIAP dataset, further improved by 4% when the temporal modality is included.