 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Learnability in the Sublinear Data Regime
Paper and Code
May 04, 2018
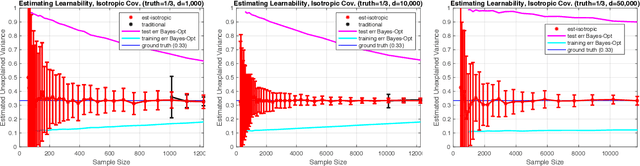
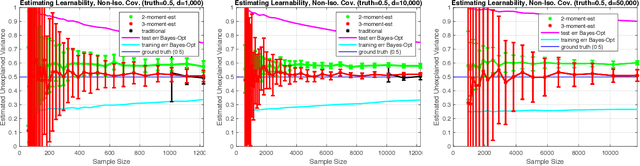
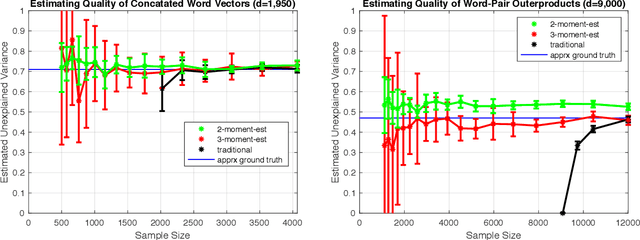
We consider the problem of estimating how well a model class is capable of fitting a distribution of labeled data. We show that it is often possible to accurately estimate this "learnability" even when given an amount of data that is too small to reliably learn any accurate model. Our first result applies to the setting where the data is drawn from a $d$-dimensional distribution with isotropic covariance, and the label of each datapoint is an arbitrary noisy function of the datapoint. In this setting, we show that with $O(\sqrt{d})$ samples, one can accurately estimate the fraction of the variance of the label that can be explained via the best linear function of the data. We extend these techniques to the setting of binary classification, where we show that in an analogous setting, the prediction error of the best linear classifier can be accurately estimated given $O(\sqrt{d})$ labeled samples. Note that in both the linear regression and binary classification settings, even if there is no noise in the labels, a sample size linear in the dimension, $d$, is required to \emph{learn} any function correlated with the underlying model. We further extend our estimation approach to the setting where the data distribution has an (unknown) arbitrary covariance matrix, allowing these techniques to be applied to settings where the model class consists of a linear function applied to a nonlinear embedding of the data. Finally, we demonstrate the practical viability of these approaches on synthetic and real data. This ability to estimate the explanatory value of a set of features (or dataset), even in the regime in which there is too little data to realize that explanatory value, may be relevant to the scientific and industrial settings for which data collection is expensive and there are many potentially relevant feature sets that could be collected.