 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Visual Relationship Understanding
Paper and Code
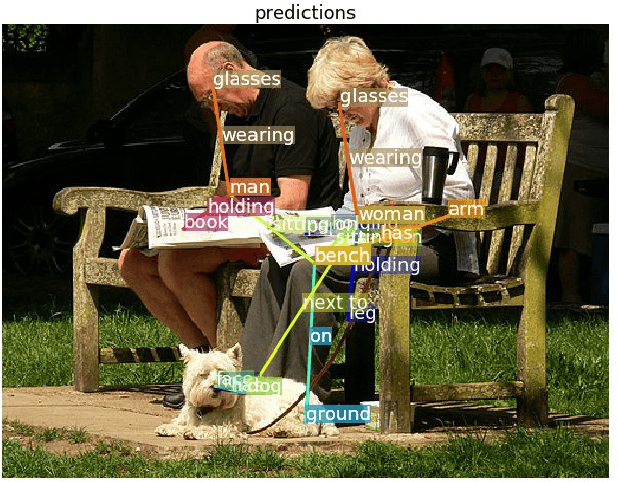
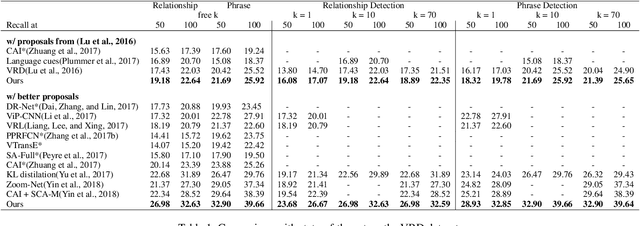
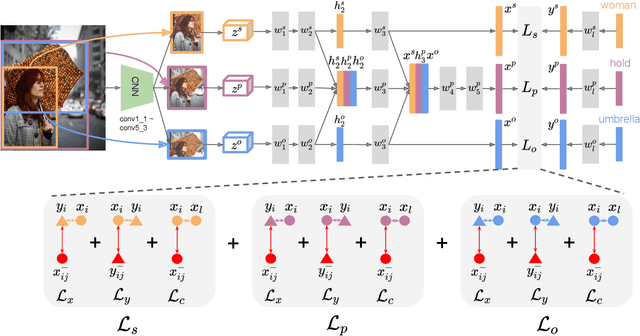
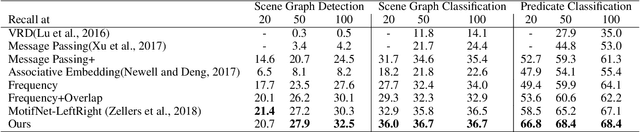
Large scale visual understanding is challenging, as it requires a model to handle the widely-spread and imbalanced distribution of <subject, relation, object> triples. In real-world scenarios with large numbers of objects and relations, some are seen very commonly while others are barely seen. We develop a new relationship detection model that embeds objects and relations into two vector spaces where both discriminative capability and semantic affinity are preserved. We learn both a visual and a semantic module that map features from the two modalities into a shared space, where matched pairs of features have to discriminate against those unmatched, but also maintain close distances to semantically similar ones. Benefiting from that, our model can achieve superior performance even when the visual entity categories scale up to more than 80,000, with extremely skewed class distribution. We demonstrate the efficacy of our model on a large and imbalanced benchmark based of Visual Genome that comprises 53,000+ objects and 29,000+ relations, a scale at which no previous work has ever been evaluated at. We show superiority of our model over carefully designed baselines on the original Visual Genome dataset with 80,000+ categories. We also show state-of-the-art performance on the VRD dataset and the scene graph dataset which is a subset of Visual Genome with 200 categories.