 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Based Natural Language Grounding by Navigating Virtual Environment
Paper and Code

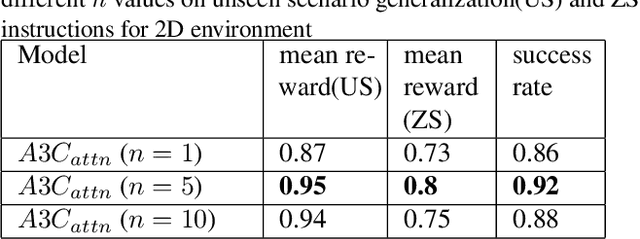
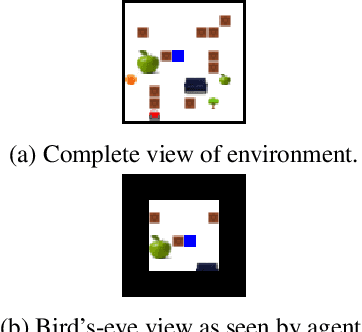
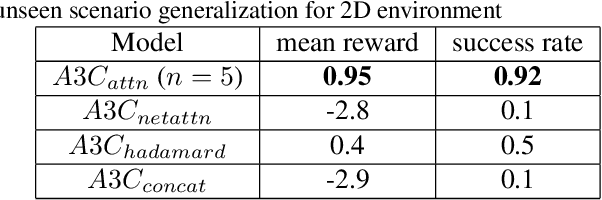
In this work, we focus on the problem of grounding language by training an agent to follow a set of natural language instructions and navigate to a target object in an environment. The agent receives visual information through raw pixels and a natural language instruction telling what task needs to be achieved. Other than these two sources of information, our model does not have any prior information of both the visual and textual modalities and is end-to-end trainable. We develop an attention mechanism for multi-modal fusion of visual and textual modalities that allows the agent to learn to complete the task and also achieve language grounding. Our experimental results show that our attention mechanism outperforms the existing multi-modal fusion mechanisms proposed for both 2D and 3D environments in order to solve the above mentioned task. We show that the learnt textual representations are semantically meaningful as they follow vector arithmetic and are also consistent enough to induce translation between instructions in different natural languages. We also show that our model generalizes effectively to unseen scenarios and exhibit \textit{zero-shot} generalization capabilities both in 2D and 3D environments. The code for our 2D environment as well as the models that we developed for both 2D and 3D are available at \href{https://github.com/rl-lang-grounding/rl-lang-ground}{https://github.com/rl-lang-grounding/rl-lang-ground}