 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multimodal Subspace Clustering Networks
Paper and Code
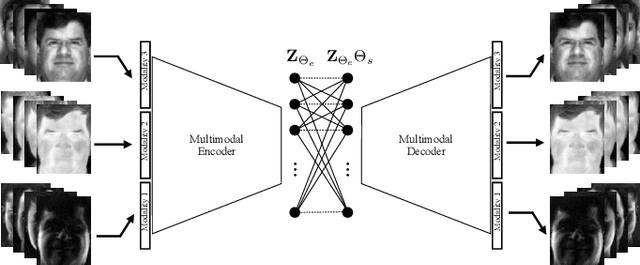
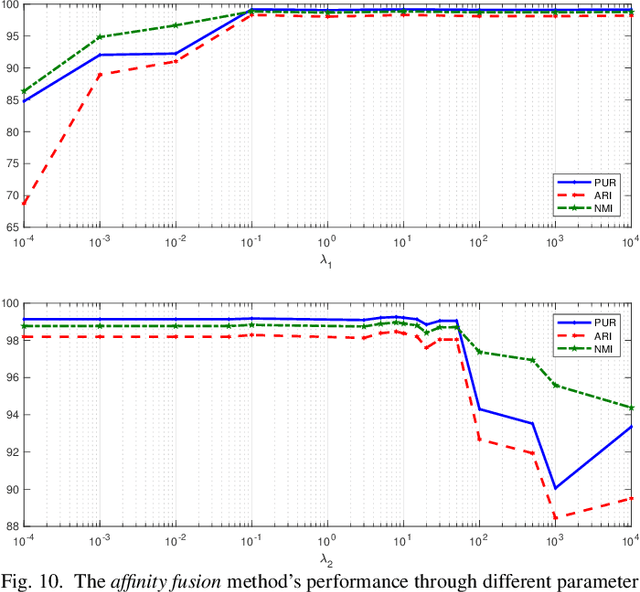
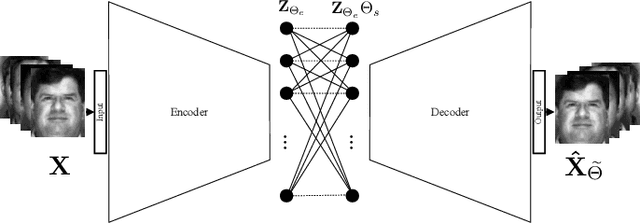
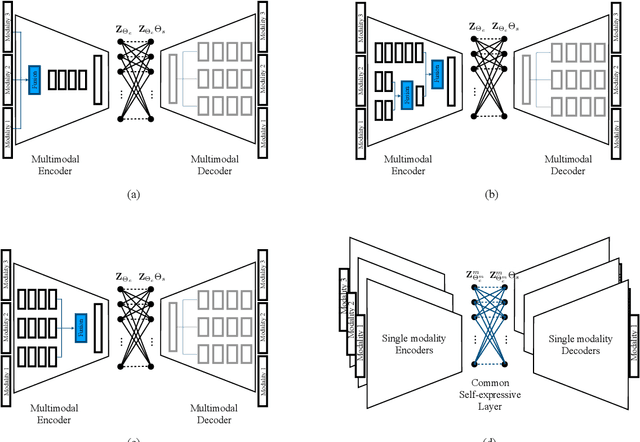
We present convolutional neural network (CNN) based approaches for unsupervised multimodal subspace clustering. The proposed framework consists of three main stages - multimodal encoder, self-expressive layer, and multimodal decoder. The encoder takes multimodal data as input and fuses them to a latent space representation. The self-expressive layer is responsible for enforcing the self-expressiveness property and acquiring an affinity matrix corresponding to the datapoints. The decoder reconstructs the original input data. The network uses the distance between the decoder's reconstruction and the original input in its training. We investigate early, late and intermediate fusion techniques and propose three different encoders corresponding to them for spatial fusion. The self-expressive layers and multimodal decoders are essentially the same for different spatial fusion-based approaches. In addition to various spatial fusion-based methods, an affinity fusion-based network is also proposed in which the self-expressive layer corresponding to different modalities is enforced to be the same. Extensive experiments on three datasets show that the proposed methods significantly outperform the state-of-the-art multimodal subspace clustering methods.